


By Ganapathi Devappa,
Beyond mapreduce
It is a great thing that time never stops or slows down (even if it did, nobody can notice it!). Mapreduce paradigm of hadoop has been around for a few years that there has to be some improved version that can do more. YARN came as mapreduce 2.0 but it has not really added anything to the functionality of map reduce. Mapreduce is a great paradigm and it provided a robust framework to execute jobs in parallel on a cluster of commodity hardware. But it cannot remain stagnant for too long.
Then came Spark which is an improvement over mapreduce paradigm. Spark extended the mapreduce paradigm by adding more functionality than map and reduce and also made many performance improvements to make it ten to hundred times faster than mapreduce. It is considered as the future mapreduce and is supposed to eventually replace mapreduce.
What is Spark?
Apache Spark is a powerful opensource parallel processing engine for big data built around speed, ease of use and sophisticated analytics. It was originally developed in 2009 in UC Berkeley’s AMP Lab and opensourced in 2010.
Apache Spark can process data from variety of datasources including HDFS, no-sql databases such Hbase and relational datastores such as hive. It can process data is in memory as well as data on disk and take advantage of data locality. It has interfaces to Scala, Java as well as Python.
Architecture
Spark works on the concept of RDDs – Resilient Distributed Datasets. RDDs are data that are distributed over a cluster of machines and are resilient. Resilient means that they can be rebuilt on failure based on the information stored. Spark works by applying a series of transformations to the RDDs. RDDs can be initially created by loading data from local storage or from HDFS. Then a series of transformations are applied to RDDs to get the resultant RDD.
Spark architecture is similar to hadoop in that it works with cluster of machines in a master-worker architecture. The architecture can be represented by the following diagram:
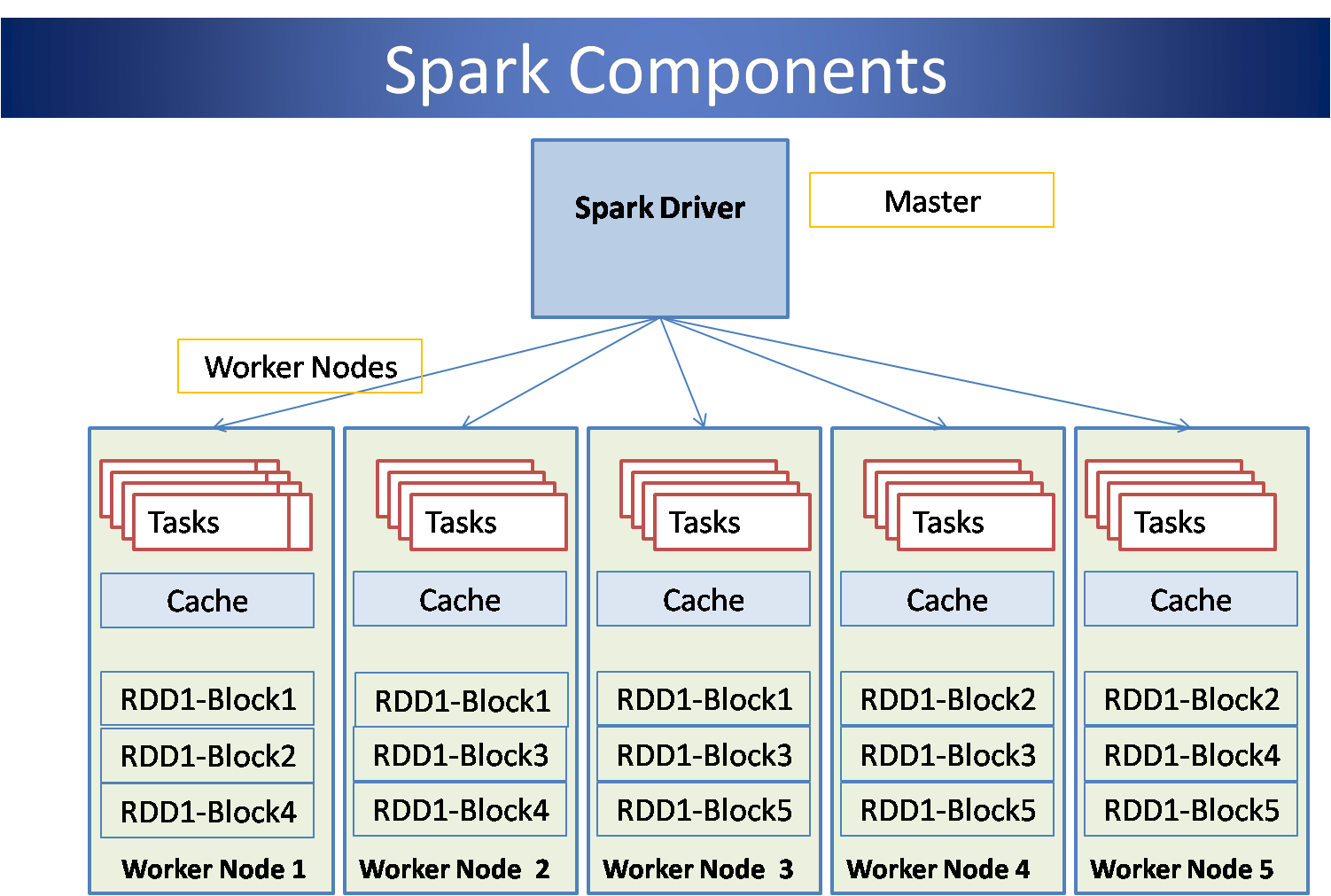
In the above diagram, Spark is storing an RDD called RDD1 which is 300MB in size. This RDD is stored using HDFS with a default replication factor of 3 and block size of 64MB.

Scala
If you are going to use Spark, it is better that you learn Scala, a highlevel language on top of Java. Scala is an object-functional language. Here is an example ‘Hello World’ program from scala:
object HelloWorld {
def main(args: Array[String]) {
println(“Hello, world!”)
}
}
HelloWorld.main(null)
you can see that this is very similar to Java. Infact some people call it ‘Java without semicolons’. You can import any java classes into scala and use them directly. Spark’s default command line interface is built with Scala and provides interface to Scala as well. So you can try programs like above, without installing Scala separately.
Spark Example
RDDs -the backbone of Spark
RDDs – Resilient Distributed Datasets form the backbone of Spark. These are immutable partitioned collection of objects on which a series of transformations can be applied to derive at the results. They are distributed across a cluster. You can use the existing HDFS cluster to store the RDDs. RDDs are stored in cache by default and are stored to disk only if persistence is required.
It may look very abstract, so let me give an example of an RDD. Every one uses wordcount example, but let me give a different example where we take an log file created by Log4J for hadoop processes and give a program to process them. Consider a log file from your HDFS data node which may have content like below:
2014-11-01 07:06:13,829 INFO DataNode: successfully registered with NN
2014-11-01 07:06:13,836 INFO BlockReport of 8227 blocks took 0 msec to generate and 7 msecs for RPC and NN processing
2014-11-01 07:06:13,837 INFO DataNode: sent block report,
2014-11-01 07:06:40,000 ERROR RECEIVED SIGNAL 15: SIGTERM
2014-11-01 07:06:40,001 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: SHUTDOWN_MSG:
2014-10-07 09:57:38,062 WARN Util: Path should be specified in a URI
We can build an RDD from above file with the below command:
val logFile = sc.textFile(“logfile”)
Let us transform this RDD by applying a filter:
val errors = logFile.filter(line => line.contains(“ERROR”))
Note that RDDs are immutable, so we cannot modify an RDD but we can get a new RDD by applying a transformation. Now let us apply an action to the RDD to find out the number of errors in the logfile:
errors.count()
This will give an out like below:
res4: Long = 1
We can apply any number of transformations in spark. In mapreduce, we are restricted to one map transformation and one reduce transformation. Spark allows you to chain transformations one after the other. It also provides more functions beyond map and reduce like filter(), groupByKey, reduceByKey, Join, Union, Cogroup, Cartesian product etc.
But still some things are very cryptic in Spark and are not very intuitive. For example, Suppose we want to count the number of log messages for each different message type. We can start by producing a key for each line, based on the message type:
val keyval = logFile.map(line => if(line.contains(“WARN”)) “WARN” else (if(line.contains(“ERROR”)) “ERROR” else “Others”))
Now to count the occurrences for each key, I have to first map each word to word and a number 1 (indicating the count) and then use the reduce by key function to aggregate as below:
val result = keyval.map(word=>(word, 1) ).reduceByKey( (a,b) => a+b)
This is certainly very cryptic and not very intuitive. Why should I map a word to (word,1) ?
Installation and setup
You can get the binary installation of Spark from Apache or from Cloudera and other distributors. I use the one from Cloudera that can be downloaded from http://d3kbcqa49mib13.cloudfront.net/spark-1.1.0-bin-cdh4.tgz. This is very easy to install by just unzipping and adding the bin directory to the path. Spark scripts are written such that from the location of the bin directory, they can derive the location of the other configuration directories.
Once installed, you can use spark-shell to execute spark as well as Scala commands.
Spark does use more memory due to its caching architecture. So you may want to shutdown your other servers like map reduce, hbase etc before you start running Spark.
SQL interface
Above installation of Spark comes with an SQL interface called spark-sql. You can easily set this up to use hive by linking to the hive configuration file from the configuration directory. With this, you can easily access your existing hive tables and process the data much faster than hive.
For example, following commands can process stocks data from a comma separated file:
spark-sql
>Create table stocks(ticker string, value int) row format delimited fields terminated by ‘,’ ;
>load data inpath ‘hdfs://<ip-address>:8120/user/ec2-user/stocks.csv’ overwrite into table stocks;
>create table result as select ticker, max(value) maxval from stocks group by ticker;
>Select max(maxval) from result;
>exit;
Machine Learning interface
Spark comes built in with a machine language library MLib. This library works with Spark RDDs and has built in support for :
- linear SVM and logistic regression
- classification and regression tree
- k-means clustering
- recommendation via alternating least squares
- singular value decomposition
- linear regression with L1– and L2-regularization
- multinomial naive Bayes
- basic statistics
- feature transformations
With the popularity of the MLib library, the other Apache machine learning project Mahout is in trouble.
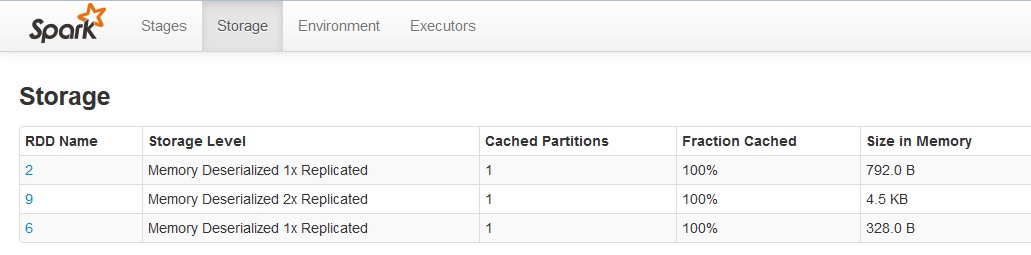
Web Interface
Like HDFS and map reduce, Spark also provides a readonly web interface at port 4040. You can use this to check the running/completed jobs as well as persistent RDDs. It may look like below:
Conclusion
Spark is providing a very viable alternative to MapReduce both in terms of performance as well as functionality. In our testing, we have found it to be much more responsive and faster for complex queries in hive compared to hive on mapreduce. Spark also interfaces with hive and hbase well, so processing existing data with Spark is a breeze. It works seamlessly with HDFS as well, so that you can process existing data with the new paradigm. Spark has already put other projects like Shark and Mahout in trouble. Future is probably with Spark-sql and Spark-MLib to process big data with a highly scalable architecture.
About the Author

Ganapathi is a practicing expert in Big data, SAP HANA and Hadoop. He has been managing database projects for many years and is consulting clients on Big Data implementations. He is a Cloudera certified Hadoop administrator and also a Sybase certified database administrator. He has worked with clients in US, UK, Australia, Japan and India on many large projects. He has helped in implementing large database projects in Sybase, Oracle, Informix, DB2, MySQL and recently SAPHANA. He has been using big data technologies like Apache Hadoop and SAP HANA and has been providing strategies for dealing with large databases and performance issues and helping in setting up big data clusters. He also conducts lot of trainings on Big Data and hadoop ecosystem of products like HDFS, mapreduce, hive, pig, Hbase, sqoop, flume, Cassandra and Spark. He is based out of Bangalore, India. He can be reached at ganapathid@spideropsnet.com.
Can you provide some use cases or case studies where Spark and Hadoop is used?
Really helpful, I am looking how to start at some point. This article helps me.