


Real Time Big Data
Apache hadoop is the most popular tool for big data processing. Hadoop is most suitable for batch and offline processing but what if real time big data processing is required? Then we have to look at other tools for distributed processing that can work in real time. We will look at one such platform of open source tools in this blog.
Use Cases
Let me mention few use cases here for real time big data:
- Telecom
A telecom operator has thousands of switches that handle thousands of calls every second. This data can be analyzed in real time to find out the most economic and reliable routing.
- Credit card
Credit card companies process millions of transactions every second and have to make quick decisions on fraud detection so that they can prevent fraudulent transactions at the earliest.
- Stock exchange
Stock exchanges handle millions of trades every second and have to keep track of stock trade information every second for thousands of stocks.
Let us look at some of the popular open source tools for real time processing.
Apache Kafka
Kafka is a highly scalable distributed message processing service. Kafka can process millions of messages per second from thousands of systems. I have found it to be extremely fast in processing messages.
Apache Kafka was originally built by LinkedIn as a distributed messaging system and later handed over to Apache Open Source in 2011. It became an Apache top level project in 2012. It is extensively used at LinkedIn. Many engineers who were working on Kafka at LinkedIn have come out and formed a separate start up under the name Confulent. (www.confluent.io).
Kafka Terminology
Messages within Kafka are grouped into categories called Topic. Each message belongs to one and only one topic. Messages are handled by the Kafka servers called brokers that are set up in a Kafka cluster. The Kafka brokers use Zookeeper for distributed coordination. The processes that publish the messages to a Kafka cluster are called producers and the processes that read the messages from the cluster are called consumers. Messages in a topic can be subdivided into one or more partitions. Partitions provide parallelism in Kafka so that messages in a topic can be handled in parallel by multiple brokers.
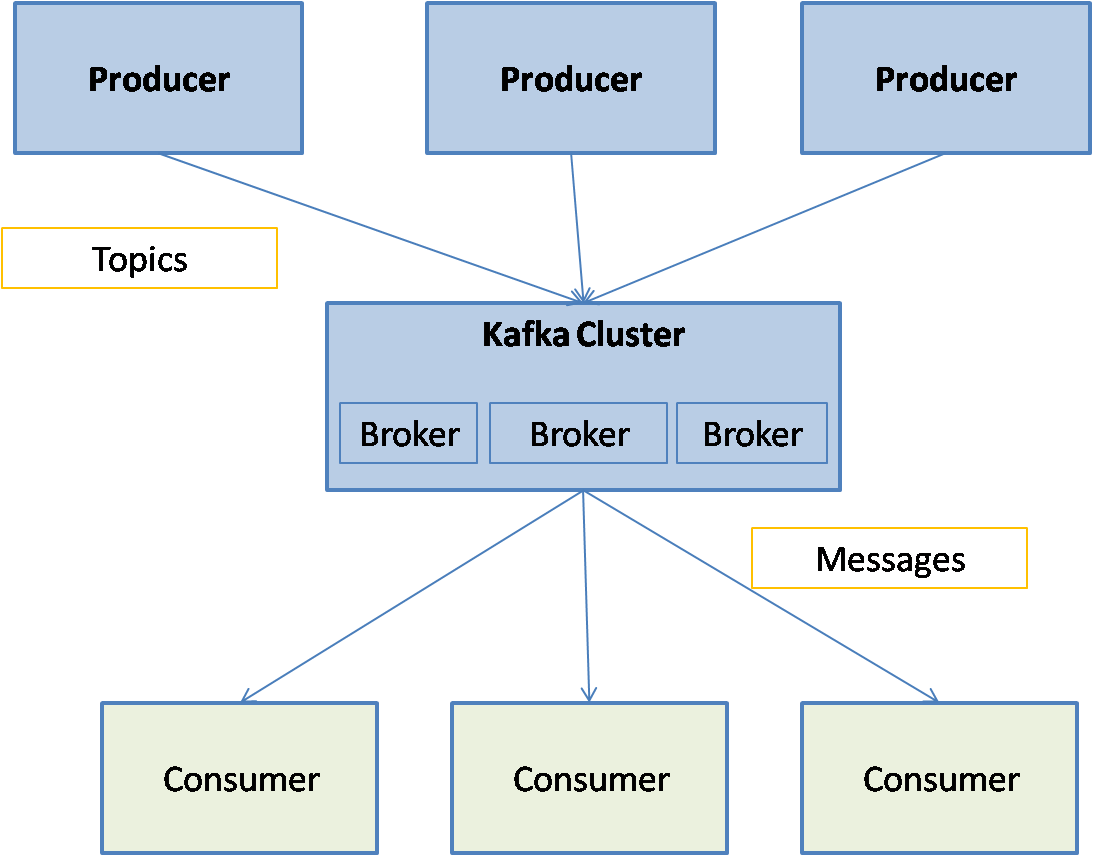
Kafka Architecture
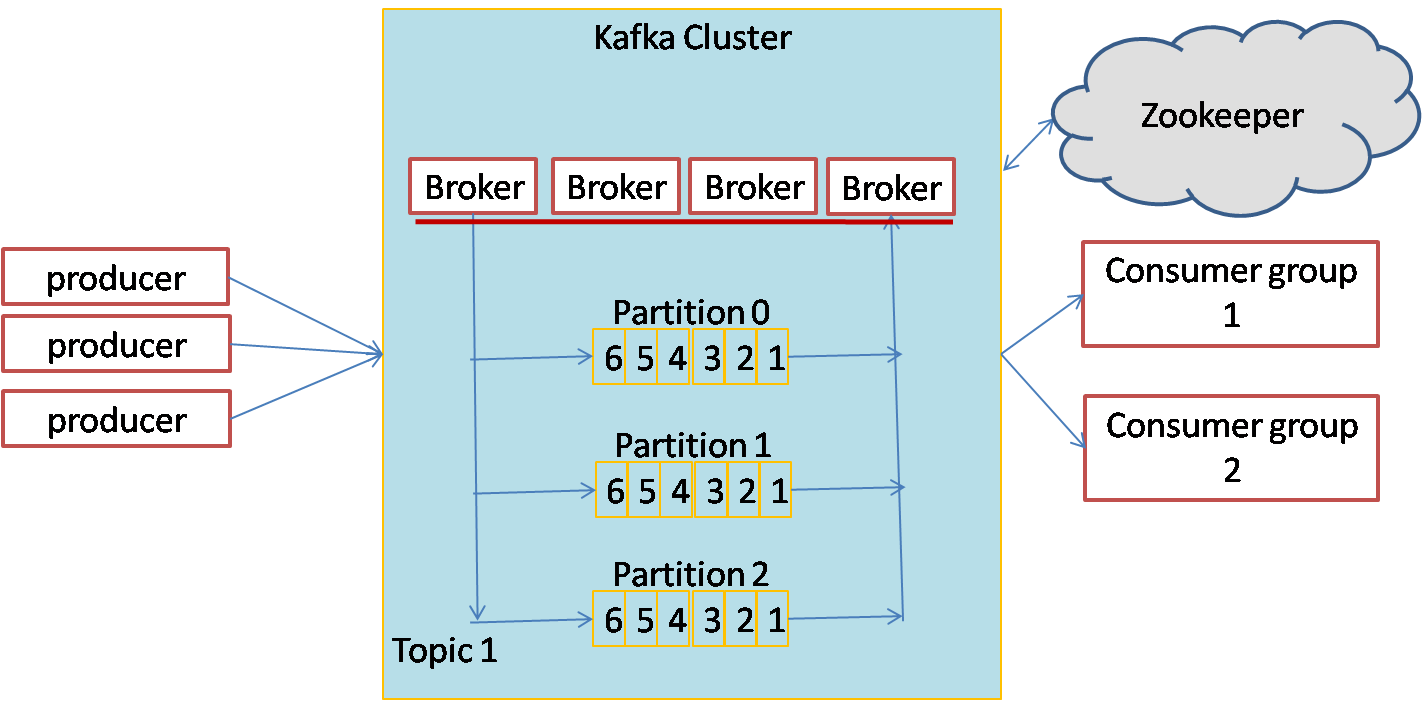
Kafka cluster consists of brokers that take the messages from the producers and provide the messages to the consumers. The messages are assigned to different partitions of the topic to achieve parallel processing. The partitions can be distributed across the Kafka cluster. Producers send the messages to the Kafka cluster and consumers retrieve the messages from the Kafka cluster. The brokers make sure messages are stored and forwarded with guarantees of fault-tolerance and message delivery order. Messages within a partition are guaranteed to be delivered in the same order as they were received.
Kafka supports both publish-subscribe and message queue type of messaging. In publish subscribe, each published message is received by all the consumers. In the message queue system, each message is received by only one consumer. Kafka consumers can be grouped together into consumer groups. Each message is received by only one consumer in each consumer group. By having each consumer in a separate consumer group, we can get publish subscribe type of messaging. By having all consumers in a single consumer group, we can get message queue type of messaging service.
Following diagram show the architecture of a Kafka messaging system:
Apache Storm
Next, let us look at Apache Storm, which is a real time stream processing system. Storm can parallelize processing of stream data and is highly reliable and scalable.
Storm data model consists of tuples and streams. A tuple is an ordered list of named values like a database row. For example the stock market data may have (‘ABC’,’10-Jun-2015 12:43:54PM EST’,123.25) as a tuple that represents the stock symbol, date time and stock traded value. A stream in Storm is an unbounded sequence of tuples. For example if the above stock market data is sent every second by the stock exchange to a broker, it becomes a stream of tuples.
Storm Topology
Storm provides two types of transformations on the streams of tuples. The processes that receive the external data and convert them to streams of tuples is called a spout. The processes that apply some transformation on the tuples and send them to output are called bolts. Bolts can send the processed tuples to output or to other bolts. The structure of spouts and bolts together is called a topology in Storm. Following diagram represents a Storm topology with one spout and six bolts:
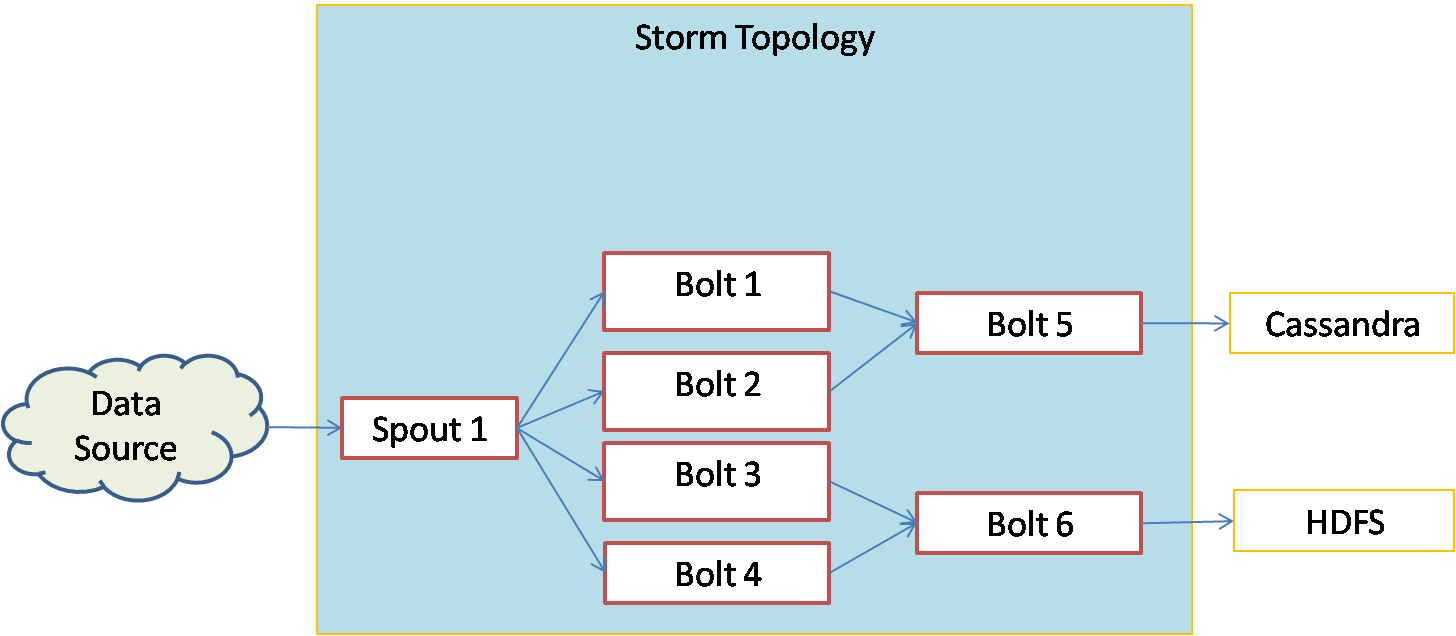
In the above topology, The spout gets the data from an external data source, forms the tuples and sends them to four bolts in parallel. The bolts 1 to 4 run in parallel and process the tuples. Bolt 1 and Bolt 2 send the processed data to Bolt 5 where as Bolt 3 and Bolt 4 send the data to Bolt 6. Bolt 5 and Bolt 6 run in parallel and produce different outputs. Bolt 5 stores the data into a Cassandra database where as bolt 6 stores the data into HDFS.
Storm uses a distributed master-slave architecture where the spouts and bolts can run on different nodes of the cluster. The master node is called the Nimbus and the slave or worker nodes are called the supervisor nodes (as they supervise the spout and bolt tasks). Storm is especially useful in dividing the input stream in multiple streams and producing different outputs. We will see how this is useful when we look at Storm working with Cassandra.
Apache Cassandra
I have done a blog earlier on Cassandra which you can read at Demystifying Apache Cassandra, A No-SQL Database. Let me summarize a bit here.
Cassandra is a high-performance, highly scalable No-SQL database with no single point of failure. Unique feature of Cassandra is that it has a ring type architecture with all nodes acting as masters, so there is no single point of failure. Cassandra also supports multiple data centers apart from distributed nodes and racks (unlike hadoop) so that you can plan your disaster recovery across geographically remote data centers.
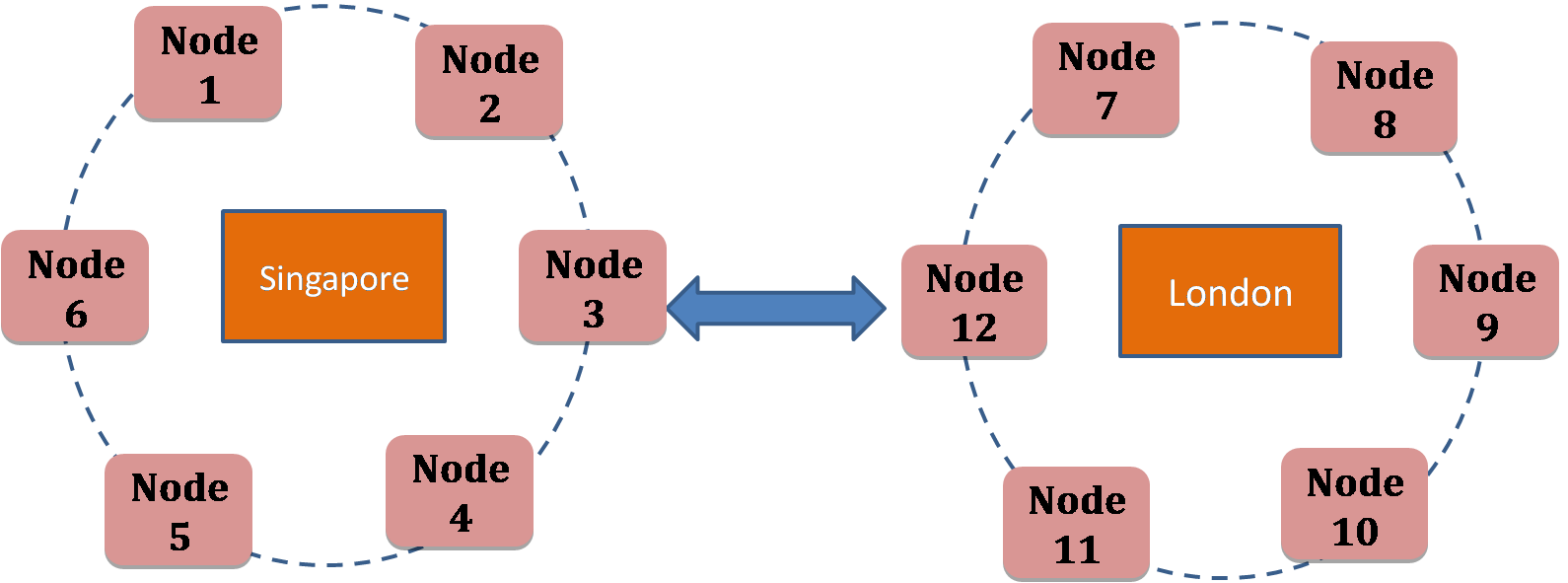
The diagram shows the Cassandra architecture with 12 nodes across two data centers. The data can be replicated across data centers so that even if the Singapore data center is down, clients can access the data from the London data center.
Another feature of Cassandra is that it provides tunable consistency for faster performance. When data is being written, client doesn’t have to wait for all the copies of data to be updated and writes can return almost immediately.
Though it is a No-SQL database, Cassandra supports basic SQL so that you can use statements like select * from employee where employeeId= 100. However, being a key-value, store, Cassandra supports only primary keys and indexed columns in the where clause. Also Cassandra does not support group by statements, which means any aggregations have to be done before data is inserted into Cassandra.
A real time big data platform
Kafka-Storm-Cassandra work together very well for real time big data processing. The architecture can be shown as below:
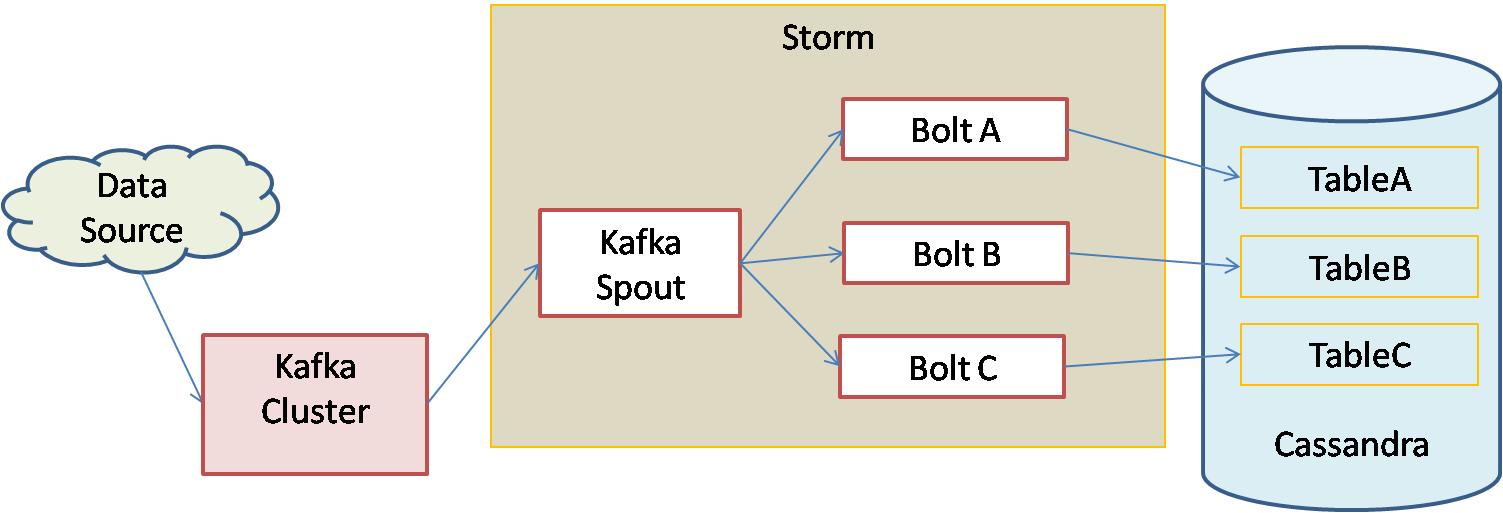
Above diagram shows the architecture for a real time big data processing. The data from the external source is sent to Kafka cluster which can process millions of records per second. This data is fed to Storm cluster through a special spout supplied by Storm called Kafka Spout. Kafka spout converts the data into tuples and sends to multiple bolts. The bolts process the data in parallel and insert the data into different tables in Cassandra. Each table in Cassandra represents a different transformation/aggregation of data.
Data Platform Example
Let us look at an example. A telecom operator generates huge amount of data every second from the switches as each second there is ingress (incoming call) and egress (outgoing call) data at the switch for thousands of calls. These are called CDR records or call data records. This data has to be stored into different tables in Cassandra by grouping at different levels. For example tableA stores data grouped by incoming mobile number, tableB is grouped by outgoing mobile number and tableC is grouped by the billing type. Here the CDR data is continuously sent to the Kafka cluster as messages which in turn sends the messages to the Storm spout. Storm spout (Kafka spout) treats each CDR record as a tuple and sends to three bolts in parallel. The bolts process the data in parallel grouping differently and insert the data into the three tables in Cassandra.
Conclusion
There are tools available now to process big data in real time. Kafka provides a way to process huge amount of incoming data generated in real time. Storm provides a way to process the stream of data in real time and provides a way to multiplex the data into multiple streams. It also processes these streams in parallel. Cassandra is a No-SQL database that provides high performance with tunable consistency. These three tools together provide a very powerful architecture for handling big data in real time.
About the Author

Ganapathi is a practicing expert in Big data, SAP HANA and Hadoop. He has been managing database projects for many years and is consulting clients on Big Data implementations. He is a Cloudera certified Hadoop administrator and also a Sybase certified database administrator. He has worked with clients in US, UK, Australia, Japan and India on many large projects. He has helped in implementing large database projects in Sybase, Oracle, Informix, DB2, MySQL and recently SAPHANA. He has been using big data technologies like Apache Hadoop, SAP HANA and Apache Cassandra and has been providing strategies for dealing with large databases and performance issues and helping in setting up big data clusters. He also conducts lot of trainings on Big Data and hadoop ecosystem of products like HDFS, mapreduce, hive, pig, Hbase, sqoop, flume, Cassandra and Spark. He is based out of Bangalore, India. He can be reached at ganapathid@spideropsnet.com.
Valuable information.