

Distributed message processing
As part of big data analytics project, you need to ingest huge amount of data in real time from external systems into your big data analytics system. You might have distributed your processing using tools like Apache Kafka but how to distribute data ingestion? That is, getting data into your big data system? This can be accomplished by a distributed message processing tool like Apache Kafka.
Apache Kafka is capable of ingesting millions of records per second from external systems into your big data system. The message processing can be distributed so that you can horizontally scale data ingestion without using expensive hardware. Big data principles of distributed data local processing and replication can be applied to Kafka to take advantage of big data technology.
Use Cases
Let me mention few use cases here for real time big data message processing using Apache Kafka:
1. Telecom
A telecom operator has millions of subscribers and gets the location data of the customers in real time. This data can be analyzed in real time to provide location specific advertisements to the consumers.
2. Cab Operators
Cab operators gets real time GPS data from their cabs and customers and need to match the customer requests to cab locations.
3. Investment bankers
Global investment bankers need to track stock prices across multiple stock exchanges and thousands of stocks in real time and provide portfolio management to their customers.
Apache Kafka
Kafka is a highly scalable distributed message processing tool. Kafka can process millions of messages per second from thousands of systems. I have found it to be extremely fast in processing messages.
Apache Kafka was originally built by LinkedIn as a distributed messaging system and later handed over to Apache OpenSource in 2011. It became an Apache top level project in 2012. It is extensively used at LinkedIn. Many engineers who were working on Kafka at LinkedIn have come out and formed a separate start up under the name Confulent. (www.confluent.com). Confluent supports opensource Apache Kafka and provides additional tools on top of Kafka base.
Kafka Terminology
Messages within Kafka are grouped into categories called Topics. Each message belongs to one and only one topic. Messages are handled by the Kafka servers called brokers that are set up in a Kafka cluster. The Kafka brokers use zookeeper for distributed process coordination. The processes that publish the messages to a Kafka cluster are called producers and the processes that read the messages from the cluster are called consumers. Messages in a topic can be subdivided into one or more partitions. Partitions provide parallelism in Kafka so that messages in a topic can be handled in parallel by multiple brokers.
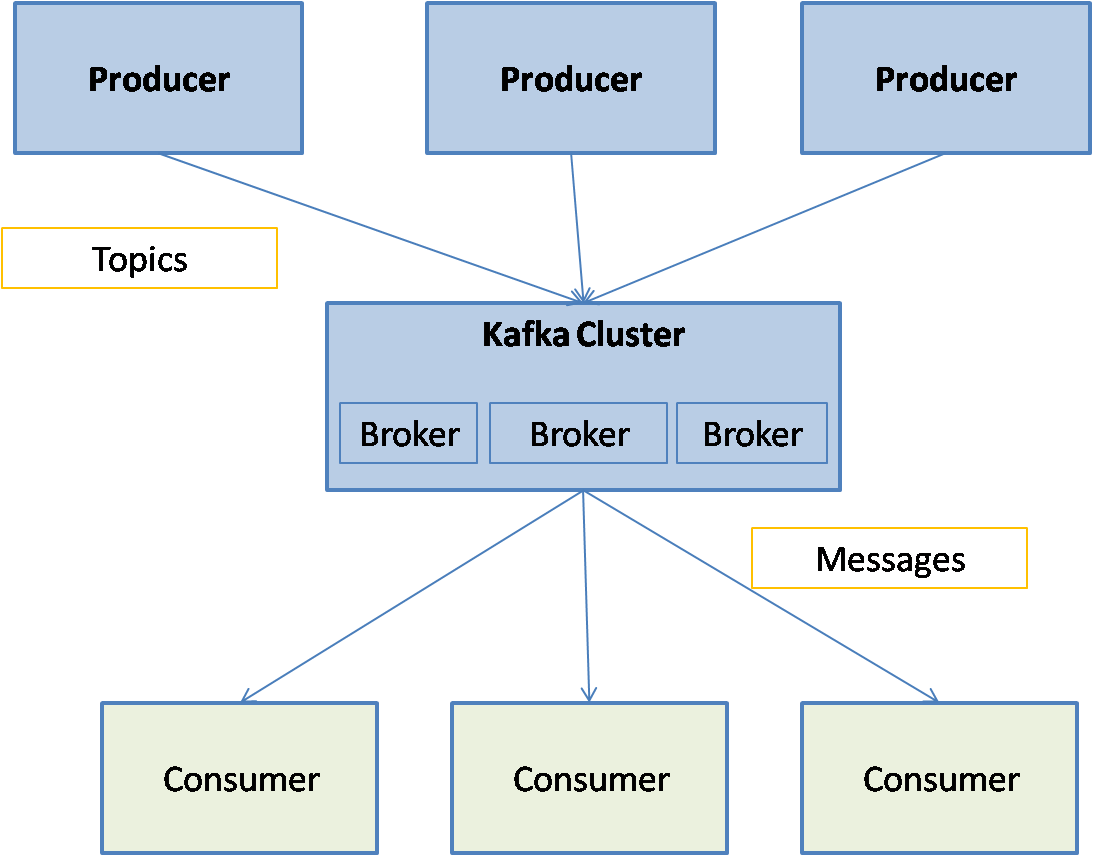
[kafka picture]
Distributed processing in Kafka
The messages in a topic have to be consumed in the same order as they are produced. This will restrict the processing of messages to one consumer and will not scale to process millions of messages per second. Kafka provides partitions for topics so that message processing can be distributed for each topic. Messages can be put into partitions in parallel and can be consumed from each partition, independent of other partitions. So if there are 100 partitions for a topic, then there can be 100 consumers that can consume messages from the topic in parallel. Also each partition can be handled by a different broker, so the processing can be distributed to 100 different brokers. So partitions provide parallelism in Kafka so that messages in a topic can be handled in parallel by multiple brokers and multiple consumers.
Fault tolerance in Kafka
Kafka uses replication of topic partitions for fault tolerance. Each topic has a replication factor specified during topic creation. Each partition of the topic is distributed to as many brokers as the replication factor for the topic. Kafka follows leader-follower method of replication. One broker is designated the leader and others brokers are designated as followers. So if the replication factor is 3, then there will be one leader broker and two follower brokers. If the leader process dies, then one of the followers becomes the leader. The leader selection recipe of Zookeeper is used to select the leader.
Kafka Architecture
Kafka cluster consists of brokers that take the messages from the producers and provide the messages to the consumers. The messages are assigned to different partitions of the topic to achieve parallel processing. The partitions can be distributed across the Kafka cluster. Producers send the messages to the Kafka cluster and consumers retrieve the messages from the Kafka cluster. The brokers make sure messages are stored and forwarded with guarantees of fault-tolerance and message delivery order. Messages within a partition are guaranteed to be delivered in the same order as they were received.
Kafka supports both publish-subscribe and message queue type of messaging. In publish subscribe, each published message is received by all the consumers. In the message queue system, each message is received by only one consumer. Kafka consumers can be grouped together into consumer groups. Each message is received by only one consumer in each consumer group. By having each consumer in a separate consumer group, we can get publish subscribe type of messaging. By having all consumers in a single consumer group, we can get message queue type of messaging service.
Following diagram show the architecture of a Kafka messaging system:
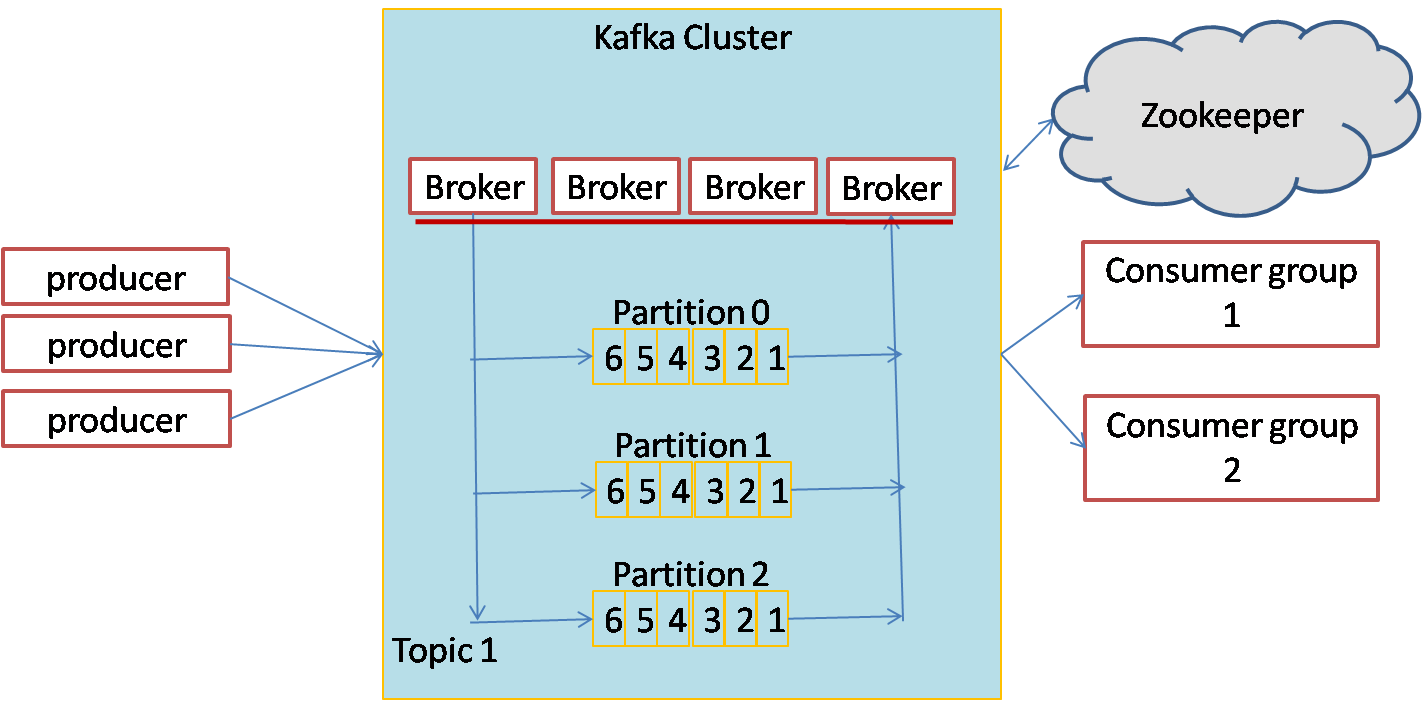
Kafka APIs
Kafka applications can be developed in Java using the Kafka client APIs provided. Both producers and consumers act as clients of Kafka. You can use the producer APIs to put messages into Kafka topics. A custom partitioner can be built to distribute the data to multiple partitions of a topic. Similarly consumer APIs can be used to get data as messages from Kafka. The consumers can be grouped together using consumer groups. The applications can be developed using IDEs like Eclipse or IntelliJ.
Conclusion
There are many tools available now to process big data in real time. Kafka provides a way to process huge amount of incoming data generated in real time using a message processing architecture. It provides distributed and fault tolerant message processing.
About the Author

Ganapathi is a practicing expert in Big data, Hadoop, Storm and Spark. He has been managing database projects for many years and is consulting clients on Big Data implementations. He is a Cloudera certified Hadoop administrator and also a Sybase certified database administrator. He has worked with clients in US, UK, Australia, Japan and India on many large projects. He has helped in implementing large database projects in Sybase, Oracle, Informix, DB2, MySQL and recently SAPHANA. He has been using big data technologies like Apache Hadoop and Apache Spark and has been providing strategies for dealing with large databases and performance issues and helping in setting up big data clusters. He also conducts lot of trainings on Big Data and hadoop ecosystem of products like HDFS, mapreduce, hive, pig, Hbase, sqoop, flume, Cassandra, Kafka, Storm and Spark. He is based out of Bangalore, India. He can be reached at ganapathid@spideropsnet.com. You also has online courses on Udemy and you can subscribe to these courses at https://www.udemy.com/user/ganapathi-devappa/