


No writings on Apache hadoop are complete without mentioning about Pig. Pig is an Apache project that acts as an interface to mapreduce.
Pig is a high level scripting language that is used with Apache Hadoop. Pig enables data scientists to write complex data transformations on mapreduce without knowing Java. Pig’s simple scripting language is called Pig Latin, and appeals to data analysts already familiar with scripting languages and SQL. It provides a data flow language to process large amount of data stored in HDFS, without writing complex mapreduce programs. It supports a variety of data types and the use of user-defined functions (UDFs) to write custom operations in Java, Python and JavaScript. Due its simple interface, support for doing complex operations such as joins and filters, Pig is popular among data scientists for performing quick query operations in hadoop.
Popularity of Pig
Pig is like the Chess term ‘Zwischenzug’, the in-between move, used by data analysts. If you ask different people, you will find different opinions about Pig.
If you ask the hadoop programmers, they will say that Pig is still immature and has not reached the stability that they can use it for production. But if you ask data scientists who have been using Pig to scrub and analyze their data, they will swear by it and will continue to use it. I think it is a good tool to use by the data scientists (for the purpose it was created for). Remember the time when ETL tools were very much in vogue? Sales people loved to use the term ‘ETL’ in their presentations and architects liked adding those extra boxes and layers in their diagrams. Many ETL tool companies and programmers made lot of money whether the tool was useful or not and companies wasted (in my opinion) lot of money on them. Unfortunately Pig does not have such patronage and sales people don’t really like saying Pig or Grunt. So it has remained a low-key project. Even the books on Pig are written by developers and not data scientists, and have not helped Pig’s cause.
So instead of talking about Pig’s structure and syntax, let me present some examples of how Pig can be used for analyzing large amounts of data. But first some basics on Pig are in order.
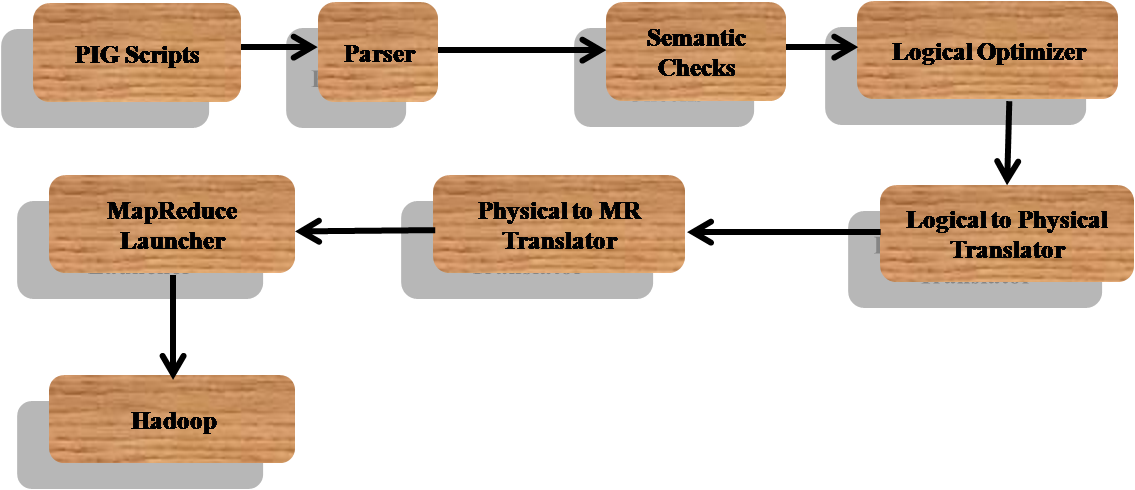
How PIG Works
Pig works with data from many sources, including structured and unstructured data, and stores the results into the Hadoop Data File System. Pig scripts are translated into a series of Map Reduce jobs that are run on the Apache Hadoop cluster.
Pig runs on hadoop and makes use of MapReduce and the Hadoop Distributed File System (HDFS). The language for the platform is called Pig Latin, which abstracts from the Java Map Reduce idiom into a form similar to SQL. Pig Latin is a data flow language which allows user to write a data flow that describes how your data will be transformed. Since Pig Latin scripts can be graphs (instead of requiring a single output) it is possible to build complex data flows involving multiple inputs, transforms, and outputs.
The user can run Pig in two modes:
- Local Mode. With access to a single machine, all files are installed and run using a local host and file system. HDFS and map reduce are not required for this. This mode can be used to test your Pig Latin scripts with small amount of data before running on a large hadoop cluster.
- Map Reduce Mode. This is the default mode, which requires access to a Hadoop cluster.
Examples
Pig Latin is the data flow language for Pig. Let us look at an example to see pig in action.
Suppose you have a large data file stored in HDFS called ‘stockdata’. You need to process this data daily. It has few bad records that need to be processed by a separate program and you don’t want them to be there in regular processing. So you will write a Pig program that separates the two sets of data and stores them separately like below ($ is the Unix/Linux shell prompt and grunt> is the pig Latin shell prompt):
$pig
grunt>data=LOAD ‘stockdata’;
grunt>badData = FILTER data BY $0 == ‘bad’;
grunt> goodData = FILTER data BY $0 != ‘bad’;
grunt>STORE badData INTO ‘baddata’;
grunt>STORE goodData INTO ‘gooddata’;
grunt>quit;
$
Above command is self explanatory, so no need to go into the details of the syntax. So without writing complicated (or simple?) mapreduce programs, we are able to produce two files in HDFS, separating the good and bad records.
Now suppose you want to find out how many bad records are there for each stock, it is easy to do this as well. Let us assume the third field contained the name of the stock or ticker symbol for the stock:
$pig
grunt>badData = LOAD ‘baddata’;
grunt>groupData = GROUP badData by $2;
grunt> countBad = FOREACH groupData GENERATE group,count(groupData);
grunt>dump countBad;
grunt>quit;
$
Note that execution of the statements happen only after the dump command is given. We are doing a grouping by the stock ticker column and for each group, generating the count of no.of values in each group (self explanatory?).
Note that when you give the dump command above and the statements get executed, you will see a series of information about the map reduce jobs being executed like below:
2014-09-18 11:25:50,661 [pool-7-thread-1] INFO org.apache.pig.backend.hadoop.executionengine.mapReduce Layer.PigCombiner$Combine – Aliases being processed per job phase (AliasName[line,offset]): M: badData[1,4],badData[3,10],countBad[6,11],groupData[4,12] C: countBad[6,11],groupData[4,12] R: countBad[6,11]
2014-09-18 11:25:50,665 [pool-7-thread-1] INFO org.apache.hadoop.mapred.MapTask – Finished spill 0
2014-09-18 11:25:50,668 [pool-7-thread-1] INFO org.apache.hadoop.mapred.Task – Task:attempt_local1747085606_0005_m_000000_0 is done. And is in the process of commiting
2014-09-18 11:25:50,673 [pool-7-thread-1] INFO org.apache.hadoop.mapred.LocalJobRunner –
2014-09-18 11:25:50,673 [pool-7-thread-1] INFO org.apache.hadoop.mapred.Task – Task ‘attempt_local1747085606_0005_m_000000_0’ done.
2014-09-18 11:25:50,673 [pool-7-thread-1] INFO org.apache.hadoop.mapred.LocalJobRunner – Finishing task: attempt_local1747085606_0005_m_000000_0
You can ignore most of them but you will know some thing is happening if some commands take lot of time to process.
Pig Latin has many such constructs to process big data and many constructs are being added in each new release.
As I mentioned earlier, data scientists like Pig as they don’t have to run to a programmer everytime they needed some different type of analysis or had to scrub the data. Also it is different from hive in that the data need not be structured.
Another feature of Pig is that it has support for UDF (user defined functions) so that you can extend the syntax to do some specific analysis work. But here the data scientist will have to work with a developer again to get this done. But once a UDF is created as per specification given by the data scientist, data scientist can use it in whatever way he/she likes it.
Conclusion:
Pig is part of the Apache hadoop project and works as a dataflow tool on top of HDFS and mapreduce. Though development community does not have a favourable view of it, data scientists like using Pig for their adhoc data analysis. It is is one of the tools in the tool kit of data scientists that frees them from developers. It is to data scientists what sed and awk tools are for Unix programmers. If this invokes your interest in Pig, then look at the references at the end.
About the Author

Ganapathi is an expert in data and databases. He has been managing database projects for many years and now is consulting clients on Big Data implementations. He is a Cloudera certified Hadoop administrator and also a Sybase certified database administrator. He has worked with clients in US, UK, Australia, Japan and India on many large projects. He has helped in implementing large database projects in Sybase, Oracle, Informix, DB2, MySQL and recently SAPHANA. He has been using big data technologies like Apache Hadoop and SAP HANA and has been providing strategies for dealing with large databases and performance issues and helping in setting up big data clusters. He is based out of Bangalore, India. He can be reached at ganapathid@spideropsnet.com.
I just wanna thank you for sharing your information and your site or blog this is simple but nice article I’ve ever seen i like it i learn something today.