


By Ganapathi Devappa,
Stream Processing
Many stream processing frameworks have come up in the last few years like Apache Storm, Apache Flink and Apache Kafka. In this blog post, I am exploring the new framework Apache Flink which tries to solve many of the problems associated with streaming. A stream refers to data that is coming continuously like the satellite location data that is being tracked every second.
What is Flink
Stream processing tools can process large amount of data that arrives in real time. Apache Storm and Spark are some such tools. Apache Flink is the new entrant to solve this problem with ease. Apache Flink is a powerful opensource framework for processing unbounded streams. It is built for big data processing with built in fault tolerance and low latency with exactly once and stateful processing. You can access Flink documentation at https://flink.apache.org
Apache Flink is part of Apache Foundation open source tools. It is most suitable for processing unbounded data : Data that is coming continuously without end. Examples of this are web application interactions, Telecom switch connection request data, Power transmission network data, Network security logs, IOT sensor data, Stock Market trade data and credit card transaction data.
Why a new framework?
Many of the existing frameworks treat the streaming data like micro-batches : a batch of records coming every second or minute. With Flink you can process these continuously as the data arrives. There is always a trade off between processing latency and fault-tolerance. Flink tool is built so that it is extremely fast and also ensures exactly once processing of data. Exactly once processing is important in streaming applications as if processing of one event fails and the event is resent, then the framework has to ensure that the same message is not processed twice. Flink has mechanism to handle out of order or late arriving data: that is if data was produced but due to some network issue comes few minutes late. Processing may need to be done in the order that data was produced rather than in the order that the data was received. It also has built in stateful processing so that you can accumulate the summary data. It is also highly scalable so that you can distribute it to run on thousands of commodity class machines that can reduce hardware cost.
Here are the features that stand out:
- Stateful processing
- Exactly once processing
- Lightweight Fault-tolerance
- Out of order data processing
- Representation of data at different levels
- Chaining of processing
- Flexible windowing
- Highly scalable to thousands of cluster nodes
Flink Usecases
Following are some of the use cases for Apache Flink:
- Updation of eCommerce product detail and inventory information in real time
- Sensor network management by early detection of errors(IOT)
- ETL processing of telecom switch data
- Game usage information processing for massively online games
- Real time stock market tips based on up to second trades and bids
Architecture
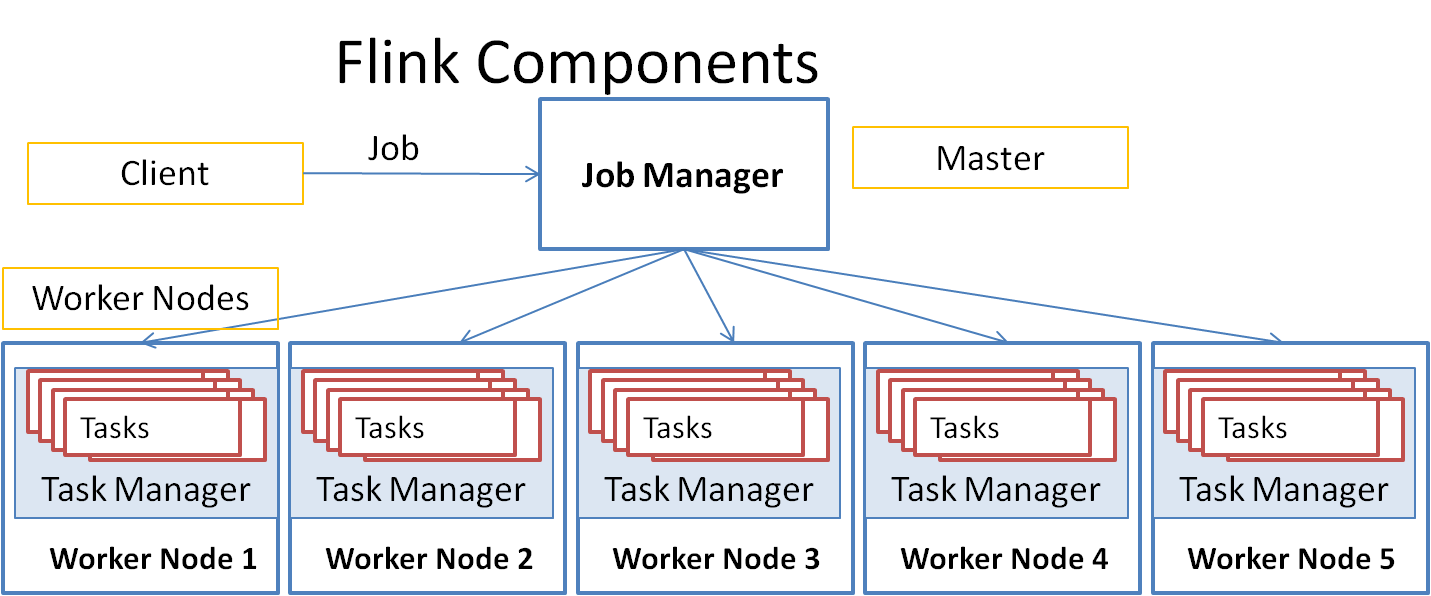
Flink architecture is similar to hadoop map-reduce in that it works with cluster of machines in a master-worker architecture. The architecture can be represented by the above diagram.
Client submits the streaming jobs to a Job Manager that runs on the master node. There is normally one manager but you can have multiple job managers for fault tolerance. Only one will be primary and others will be on stand by.
A job is divided into tasks and the Job manager schedules the tasks on the task managers running on worker nodes. Unlike hadoop where each task runs on a separate JVM, the task manager runs the tasks in a single JVM so that it is more efficient to share the state information among tasks. Note that the tasks running in a single JVM run on separate threads that have a shared memory.
The client jobs can be built as a scala jar or java jar. Flink also provides a scala shell that can run Flink tasks.
Flink Dataflow
Data flow in Flink is organized into three parts as below:

Source: Data from external systems that is streamed into Flink.
Flink provides connectors to various external sources of data including:
- Apache Kafka (A messaging system)
- RabbitMQ (A messaging system)
- Amazon kinesis streams
- Apache Nifi
- Socket stream
- File based batch source
- Program objects
This is quite limited but as usage increases, more external products are expected to provide connectors for Flink.
Transformations: The processing of data within Flink. Flink provides various mechanisms to represent and transform the data and these transformations can be chained together. Spark like transformations like map, filter, join are supported. Map applies a function to each event in the data and outputs a modified event. Filter outputs only the events that satisfy the given predicate. join is used to combine events from multiple streams.
Sink: Sinks are used to output the data after processing. Following sinks are supported:
- File
- Socket
- HDFS
- Apache Kafka
- Elastic Search
- RabbitMQ
- Amazon kinesis streams
- Apache Nifi
- Apache Cassandra
- Apache Bahir
- Program objects
Flink Example
Let us look at some sample processing of streaming data using the Flink scala shell. Below commands assume that you have installed Flink and you are in the root directory of the installation.
#Start the Flink scala shell
./bin/start-scala-shell.sh local
// Create a dataset from program object. senv is the default streaming environment
val ds1 = senv.fromElements(1,2,3,4,5,6,7,8,9,10)
// Apply map transformation to increment the number
val ds2 = ds1.map(x=>x+1)
// Apply filter transformation to get values less than 8
val ds3 = ds2.filter(_ < 8)
/ / output the results on the console
ds3.print()
// Start the stream execution
senv.execute(“start running”)
// Quit the scala shell
:quit
Output:
2
3
4
5
6
7
As you can see above, use of transformations like map and filter make it very easy to process the streams. In scala shell, the streaming environment is provided as senv where as if you compile a program to run, then the environment has to be created explicitly.
Flink uses lazy processing, so the stream processing starts only after senv.execute is called above.
In the above example, the streaming data source was from program objects. You can also use a socket like senv.socketTextStream or Kafka messaging like senv.addSource(kafkaConsumer). Similarly senv.print sends the output to standard output where as it can be sent to a Kafka topic using senv.addSink(kafkaProducer). It can also be sent to other sinks. You can see some of the examples on github at https://github.com/apache/flink/tree/master/flink-examples/flink-examples-streaming/src/main/scala/org/apache/flink/streaming/scala/examples
Installation and setup
You can get the binary installation of Flink from Apache Flink site at https://flink.apache.org/downloads.html.
Many people install their hadoop, Spark, Kafka and Storm installation from Hortonworks HDP platform or Cloudera’s Cloudera manager platform. As of this writing, Flink is not yet available on these platforms which may limit its widespread use.
You can download the tarball and untar it (using tar -xvf) in the target directory. You can change your path to include the bin directory and you are all set to use Flink. For using Flink scala shell, no additional steps are required.
Data representation levels
Flink provides various levels of data representation to make it easier to process the streaming data. Following four levels are currently supported:
Stateful Stream processing: This is the lowest level and provides access to raw data as events and states. Most programs do not need to process at this level.
DataStream processing: This represents the data as a datastream as we showed in our example. This can be processed as data having a type like a tuple and individual fields can be accessed. You can associate a schema with the datastream using case classes.
Table processing: This provides declarative processing by representing the data as a table so each event is like a table row with a schema attached.
SQL processing : This is similar to the table processing with further SQL type query processing on the data. Queries like “select * from employee where id = 100” are supported.
Deployment
Flink can be deployed as standalone on a single machine. This is suitable for development and testing. For production, a distributed cluster environment is preferred. Here you have the choice of using the built in cluster manager or using another cluster manager like YARN. You can also use cloud based deployment environments like Amazon EC2 or Google cloud.
Batch Processing
Though Flink is primarily designed for real time stream processing, it can be used for batch processing files using a different run time environment called batch environment. You can use a file as input here and sink can be any of the other sinks.
Conclusion
While there are many stream processing frameworks available, Apache Flink provides a good alternative that claims to take care of many of the challenges faced in stream processing like latency and exactly once processing. Chaining of source, transformations and sinks makes it easier to use compared to Apache Storm. It still needs to add more sources and sinks. Considering that Apache Spark has added structured streaming in the recent versions that uses continuous streaming instead of micro-batching, Flink may find it difficult to sustain development. Also non availability on HDP and Cloudera platforms need to be overcome.
About the Author

Ganapathi is a practicing expert in Big data, SAP HANA and Hadoop, Storm and Spark. He has been managing database projects for many years and is consulting clients on Big Data implementations. He is a Cloudera certified Hadoop administrator and also a Sybase certified database administrator. He has worked with clients in US, UK, Australia, Japan and India on many large projects. He has helped in implementing large database projects in Sybase, Oracle, Informix, DB2, MySQL and recently SAPHANA. He has been using big data technologies like Apache Hadoop and SAP HANA and has been providing strategies for dealing with large databases and performance issues and helping in setting up big data clusters. He also conducts lot of trainings on Big Data and hadoop ecosystem of products like HDFS, mapreduce, hive, pig, Hbase, sqoop, flume, Cassandra, Kafka, Storm and Spark. He is based out of Bangalore, India. He can be reached at ganapathid@spideropsnet.com.