


By Ganapathi Devappa
Apache hadoop is supposed to assist in big data analytics. But most analysts are not familiar with java programming. Many of them have come to learn SQL. Though hadoop mapreduce made parallel programming simpler, analysts had to depend on programmers to write programs on mapreduce. So a workaround with SQL interface called hive was created.
Apache hive is an open source database system initially developed by facebook and built on top of hadoop framework for querying and analyzing large data sets stored in HDFS files.
Hive provides a SQL-like language called HiveQL or HQL. Due to its SQL-like interface, hive is increasingly becoming the technology of choice for using hadoop by data analysts. It can process petabytes of data by dividing the job automatically into parallel mapreduce tasks. The jobs that could take days for analysts can be done in hours or minutes without taking the trouble of programming in java.
Apache hive does remind me of capturing bee hives in the wild during child hood days but comes without the nasty bee stings.
Hive is not designed for online transaction processing and does not offer real-time queries and row level updates. It is best used for batch jobs over large sets of immutable data.
Advantages of Hive
Hive provides,
- Tools to enable easy data extract/transform/load.
- A mechanism to impose structure on a variety of data formats
- Access to files stored either directly in Apache HDFS or in other data storage systems such as Apache HBase
- Query execution via Map Reduce
Hive Architecture
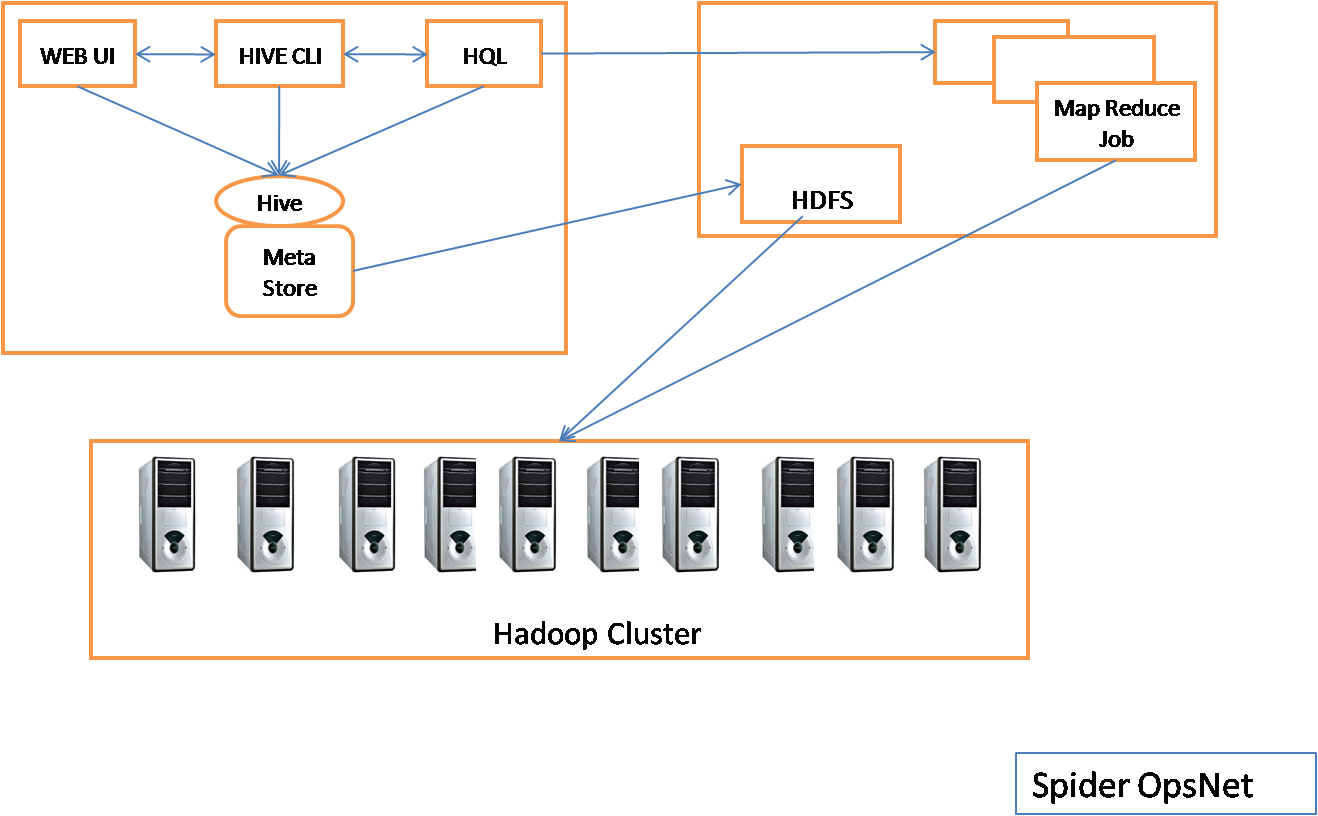
Hive Components
- UI – The user interface for users to submit queries and other operations to the system. Currently the system has a command line interface (CLI) called hive shell and a web based GUI called hwi service. It also provides jdbc/ODBC interface through hiveserver2 service. While CLI interface is available by default, hwi and hiverserver2 services need to be explicitly started.
- Hive Service
o Driver – The component which receives the queries. This component implements the notion of session handles and provides execute and fetch APIs modeled on JDBC/ODBC interfaces.
o Query Compiler – The component that parses the query, does semantic analysis on the different query blocks and query expressions and eventually generates an execution plan with the help of the table and partition metadata looked up from the Metastore.
o Execution Engine – The component which executes the execution plan created by the compiler. The execution engine manages the dependencies between different stages of the plan and executes these stages on the appropriate system components.
- Metastore – The component that stores all the structure information of the various table and partitions in the warehouse including column and column type information, the serializers and deserializers necessary to read and write data and the corresponding hdfs files where the data is stored. This can be part of hive or can be stored separately for multi-user access.
Hive Example
Since most people are familiar with SQL, let me start with an example so that you know how hive works like.
I have created a file ‘document’ with following content on linux ($ below is the linux shell prompt):
$cat document
1,James,Winfrey,40,banker
2,Jack,Daniel,25,programmer
3,Lina,Davis,30,manager
4,Linda,Goodman,42,programmer
5,Shiv,Rao,34,data scientist
We can put this file into HDFS with the following command:
$hdfs dfs –put document
Now that we have the data file in HDFS, let us start hive shell. ‘hive>’ is the command prompt for hive shell:
$hive
hive> CREATE TABLE customer (custid INT, firstname STRING, lastname STRING, age INT, profession STRING) row format delimited fields terminated by ‘,’;
Above command creates the meta data for the table customer. I have removed lot of information messages displayed by hive shell. Note the ‘;’ at the end of the line to terminate the command.
Let us check the table definition:
hive> describe customer;
OK
custid int
firstname string
lastname string
age int
profession string
Let us load the data into table using the HDFS file we created:
hive> LOAD DATA INPATH ‘document’ INTO TABLE customer;
hive> select * from customer;
OK
1 James Winfrey 40 banker
2 Jack Daniel 25 programmer
3 Lina Davis 30 manager
4 Linda Goodman 42 programmer
5 Shiv Rao 34 data scientist
Time taken: 0.759 seconds
Let us find the number of customers for each profession:
hive>select profession,count(*) from customer group by profession;
banker 1
programmer 2
manager 1
scientist 1
Above command is executed by hive by creating mapreduce jobs for the query and submitting to mapreduce. You can see that writing many lines of mapreduce code in java is avoided by using hive.
How Hive Works?
The tables in Hive are similar to tables in a relational database, and data units are organized in taxonomy from larger to more granular units. Databases are comprised of tables, which are made up of partitions. Hive supports overwriting or appending data, but not updates and deletes.
Within a particular database, data in the tables is serialized and each table has a corresponding Hadoop Distributed File System (HDFS) directory. Each table can be sub-divided into partitions that determine how data is distributed within sub-directories of the table directory. Data within partitions can be further broken down into buckets.
Hive Physical Layout:
- Its default warehouse directory is in HDFS.e.g. /user/hive/warehouse
- Tables are stored in the subdirectories of this warehouse directory. Partitions form subdirectories of tables.
- The actual data is stored in flat files. Flat files can be character-delimited text or Sequence files.
Hive Services
Hive provides various services for external interfaces. I will mention two of these services here.
Web interface: hwi service
This can be started as
hive –service hwi
Then you can access the hive system using your browser as:
<IP address>:9999/hwi
Here you can access the hive command documentations with :
<IP address>:9999/hwi/docs
[Ip address is hidden above for our security]
JDBC interface
This can be started with the service as:
hive –service hiveserver2
Once started, you can use jdbc through java programs to connect to the server. The jdbc connection string is:
jdbc:hive2://<host>:<port>/<db>
The default port is 10000. Default database is ‘default’.
Hive Capabilities
Hive query language provides the basic SQL like operations. These operations work on tables or partitions. These operations are:
- Ability to filter rows from a table using a where clause.
SELECT * FROM customers WHERE custid=4;
- Ability to select certain columns from the table using a select clause.
SELECT firstname, profession FROM customer;
- Ability to do joins between two tables.
SELECT a.firstname, a.profession, b.mailid FROM customer a JOIN mails b ON a.firstname=b.custname;
- Ability to evaluate aggregations on multiple “group by” columns for the data stored in a table.
SELECT category, SUM(amount) FROM category GROUP BY category;
- Ability to store the results of a query into another table.
CREATE table resultcategory as SELECT * FROM category;
- Ability to download the contents of a table to a local directory.
INSERT OVERWRITE LOCAL DIRECTORY ‘hiveresult’ SELECT * FROM category;
- Ability to manage tables and partitions etc. (I will explain this next)
CREATE TABLE customer (custid INT, firstname STRING, lastname STRING, age INT, profession STRING) partitioned by (category STRING) clustered by (firstname) INTO 10 buckets row format delimited fields terminated by ‘,’ stored as textfile;
Hive Data Model
In the order of granularity – Hive data is organized into:
- Databases: Namespaces that separate tables and other data units from naming conflicts.
- Tables: Homogeneous units of data which have the same schema.
- Partitions: Each Table can have one or more partition keys which determine how the data is stored.
- Buckets (or Clusters): Data in each partition may in turn be divided into buckets based on the value of a hash function of some column of the table.
Data Types
Primitive types:
- TINYINT – 1 byte integer
- SMALLINT – 2 byte integer
- INT – 4 byte integer
- BIGINT – 8 byte integer
- BOOLEAN – TRUE/FALSE
- FLOAT – single precision
- DOUBLE – Double precision
- STRING – sequence of characters in a specified character set
Complex Types:
- arrays: ARRAY<data_type>
- maps: MAP<primitive_type, data_type>
- structs: STRUCT<col_name : data_type [COMMENT col_comment], …>
- union: UNIONTYPE<data_type, data_type, …> (Only available starting with Hive 0.7.0)
Hive Query Language
Hive Query Language (HQL) statements are similar to standard SQL statements.
you can run Hive queries in many ways. From a command line interface (known as the Hive shell), from a Java Database Connectivity (JDBC) or Open Database Connectivity (ODBC), application leveraging the Hive JDBC/ODBC drivers, or from what is called a Hive Thrift Client. The Hive Thrift Client is much like any database client that gets installed on a user’s client machine. It communicates with the Hive services running on the server. User can use the Hive Thrift Client within applications written in C++, Java, PHP, Python, or Ruby.
The example provided earlier was based on hive shell.
Hive Commands
List Databases;
To List out the databases in Hive warehouse,
Show databases;
Create Database:
The database creates in a default location of the hive warehouse.
CREATE DATABASE database_name;
Change to created Database:
| use DATABASE database_name ; |
Alter Database:
ALTER DATABASE database_name SET OWNER user_or_role; (Hive 0.13.0 and later)
DDL commands:
Create Table:
CREATE TABLE customer (custid INT, firstname STRING, lastname STRING, age INT, profession STRING) row format delimited fields terminated by ‘,’ STORED AS textfile;
Describe Table:
Describe customer;
Drop Table:
DROP TABLE customer;
Alter Table:
ALTER TABLE customer RENAME TO customers;
DML Commands:
Load Data:
LOAD DATA INPATH ‘document_name’ INTO TABLE customers;
Insert Data:
INSERT OVERWRITE TABLE newcategory SELECT * FROM category;
Partition:
PARTITIONED BY is used to divide the table into the PARTITION and we can divide the PARTITION in to Buckets by using the CLUSTERED BY command.
Command to enable the dynamic partition is: set hive.exec.dynamic.partition=true;
CREATE TABLE customer (custid INT, firstname STRING, lastname STRING, age INT, profession STRING) partitioned by (profession STRING) clustered by (firstname) INTO 10 buckets row format delimited fields terminated by ‘,’ stored as textfile;
Aggregation:
SELECT count (*) FROM category;
Group By:
SELECT category, SUM (amount) FROM category GROUP BY category;
JOIN:
SELECT a.firstname, a.profession, b.mailid FROM customer a JOIN mails b ON a.firstname=b.custname;
Left outer join:
SELECT a.firstname, a.profession, b.mailid FROM customer a LEFT OUTER JOIN mails b ON a.firstname=b.custname;
Right outer join:
SELECT a.firstname, a.profession, b.mailid FROM customer a RIGHT OUTER JOIN mails b ON a.firstname=b.custname;
Conclusion
For those who are not familiar with java, hive provides a platform for using sql to make use of big data hadoop platform. Though it doesn’t provide real time data access, it enables big data analysts to analyze data using familiar sql interface. With hive, analysis jobs that tooks days to get results can be accomplished in hours or minutes. The hadoop economy of running on commodity hardware makes it even more business friendly.
About the Author

Ganapathi is an expert in data and databases. He has been managing database projects for many years and now is consulting clients on Big Data implementations. He is a Cloudera certified Hadoop administrator and also a Sybase certified database administrator. He has worked with clients in US, UK, Australia, Japan and India on many large projects. He has helped in implementing large database projects in Sybase, Oracle, Informix, DB2, MySQL and recently SAPHANA. He has been using big data technologies like Apache Hadoop and SAP HANA and has been providing strategies for dealing with large databases and performance issues. He is based out of Bangalore, India. He can be reached at ganapathid@spideropsnet.com.