

By Ganapathi Devappa
Apache Hadoop has become synonymous with Big Data. Nobody talks about Big Data without doing something with Hadoop. In this blog, I try to introduce Apache Hadoop to those in the industry who want to just know what is this Hadoop all about.
Big Data Proliferation
Initially the creation of digital data was limited due to the time it took to create the data and also number of people who were producing the digital data. But in the last few years, the time it took to create the data has reduced drastically. There are even instruments called sensors that can produce data even when not attended by a human being and that too at rates of many times per second. So the number of data creators has increased many folds. Even people are producing digital even for more hours in a day, even when they are not in the office, commuting and even on weekends.
This has lead to the proliferation of data and is now being referred to as Big Data. Big data is supposed to have three main characteristics, Volume, Velocity and Variety, called the 3 Vs of Big Data.
Traditionally, relational databases are being used to store large quantity of data in data warehouses supported by Storage Area Networks for efficient storage. All data is stored in one place and data is brought to the processing machines with very powerful CPU’s with multi-core processors and large amount of memory costing millions of dollars.
This had the scalability limits as data grew to Peta bytes (~thousand Terabytes) . The technology cost was becoming increasingly prohibitive.
That is how Hadoop came about. Hadoop has the following characteristics:
1. Data stored on clusters of commodity hardware
2. Data distributed over the nodes in the cluster
3. Processing is also distributed to the nodes in the cluster
4. Processing goes to data, ie. Processing happens where the data resides instead of data coming to where the processing is done.
5. Data is replicated across multiple nodes to create redundancy and fault tolerance.
6. Highly fault tolerant processing – if processing on one node fails, it is automatically executed on other nodes
7. Share nothing architecture among cluster nodes so that massive parallelism can be achieved.
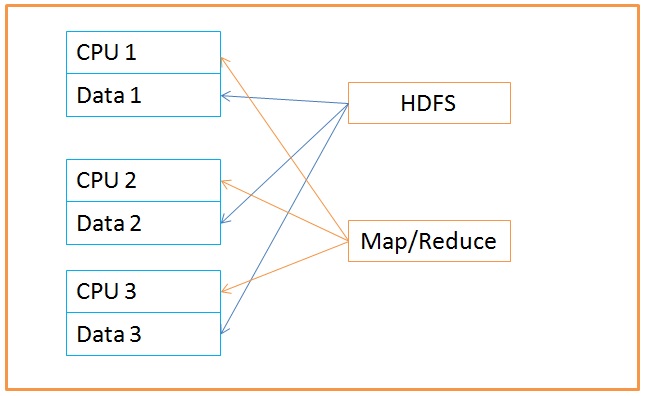
Hadoop contains two base products that implement the above functionality.
HDFS – The file system of Hadoop
HDFS, Highly distributed file system provides a distributed file system. Here the files are divided into blocks and blocks are stored on a cluster of machines. Each block is replicated and at least three copies of each block are stored on different machines. This way even if one or two machines fail, you will have a copy of the block and hence can get a copy of the file as well. HDFS follows the following designs to better manage huge data:
1. Write once read multiple times : In HDFS, you cannot modify the contents of a file, though you can append to a file. So the reads can happen without worrying about changed data contents.
2. streaming reads: Data is streamed to the process in large chunks thus minimizing average read speed. Throughput is more important than latency of access. So random reads are not encouraged and full block reads are expected. You are supposed to read the entire block of data not just few lines of data at random. This means large files can be read and processed quickly by getting the entire data in one shot.
3. Move computation to data rather than moving data to computation: Data local processing is encouraged. Processing is done on the same node where a block of data is present, so that network traffic and transfer of data across network can be reduced.
Map Reduce: The processing framework
Map reduce provides the framework for highly parallel processing of data across clusters of commodity hardware. The framework splits the data into smaller chunks that are processed in parallel on cluster of machines by programs called mappers. The output from the mappers is then consolidated by reducers into the desired result. The share nothing architecture of mappers make them highly parallel and similarly share nothing architecture of reducers make them highly parallel as well.
An illustration will make this more clear. Let us take an example of stock price of XYZ stock every minute over the last ten years. Assuming about 250 trading days in a year and six hour trading in a day, we will get about 9 Million records. If you are storing 100 bytes per record, this will be 900MB of data (not very large but if you are tracking 100 such stocks, it will become 90GB of data!).
Storing in HDFS: You can store this 900 MB of data in HDFS (say comma separated lines). HDFS divides this into blocks of 64MB size and by default will give 15 blocks. With a replication factor of 3, this will become 45 blocks that will be stored on different machines of the cluster. If we take the first 5 blocks and if there are five machines to store data, it may be stored as follows:
Machine 1: Block1, Block2, Block4
Machine 2: Block1, Block3, Block4
Machine 3: Block1, Block3, Block5
Machine 4: Block2, Block3, Block5
Machine 5: Block2, Block4, Block5
As you can see, each block is stored on 3 machines. Even if any two machines fail, data will be available in other machines. For example if machine 1 and machine 2 fail, data can be retrieved as follows:
Block1: Machine 3
Block2: Machine 4
Block3: Machine 3
Block4: Machine 5
Block5: Machine 4
Map Reduce processing:
Suppose we want calculate the minimum and maximum values for the stock from the data, then mappers and reducers will work as follows:
Mapper:
for each block of data, output the minimum value, maximum value and the date and time for the minimum and maximum values.
Assuming the input splits for the mapper are same as data blocks, there will be 15 mappers each outputting two records, one for minimum and one for maximum values.
| 12-Mar-2014 11:09 AM 34.56 | MAX 12-Mar-2009 10:01 AM 35.34 |
| 12-Mar-2014 11:10 AM 33.21 | MIN 15-Mar-2009 03:31 PM 30.21 |
| ………….. |
If we take the first five blocks distributed as above, the mappers may run as follows:
Mapper 1: Block 1, Machine 1
Mapper 2: Block 2, Machine 4
Mapper 3: Block 3, Machine 2
Mapper 4: Block 4, Machine 5
Mapper 5: Block 5, Machine 3
As you can see all the 5 tasks can run in parallel and data is local to the process where it is run.
Reducer:
Sort the data and get the minimum and maximum values.
Reducer will get only thirty total records to process (two from each mapper), so one reducer is enough to do this job and out put the required result.
| MAX 12-Mar-2009 10:01 AM 35.34 | MAX 20-Jun-2012 12:05 PM 40.35 |
| MAX 20-Jun-2012 12:05 PM 40.35 | MIN 21-Dec-2011 01:12 PM 27.32 |
| ………….. | |
| MIN 15-Mar-2009 03:31 PM 30.21 | |
| MIN 21-Dec-2011 01:12 PM 27.32 | |
| ………………. |
Hadoop is a very powerful framework that can handle hundreds of cluster nodes in parallel in an efficient fault-tolerant way. The share nothing architecture allows massive parallelism and data-local block oriented processing ensures in-memory processing of data.
Hadoop also makes economic sense as instead of spending as much as $50,000 per Terabyte of data processing with current RDBMS architectures, Hadoop can be implemented for less than $2000 per Terabyte of data processing.
Some references:

Ganapathi is an expert in data and databases. He has been managing database projects for many years and now is consulting clients on Big Data implementations. He is a Cloudera certified Hadoop administrator and also a Sybase certified database administrator. He has worked with clients in US, UK, Australia, Japan and India on many large projects. He has helped in implementing large database projects in Sybase, Oracle, Informix, DB2, MySQL and recently SAPHANA. He has been using big data technologies like Apache Hadoop and SAP HANA and has been providing strategies for dealing with large databases and performance issues. He is based out of Bangalore, India. He can be reached at ganapathid@spideropsnet.com.
Great content useful for all the candidates of Hadoop Training who want to kick start these career in Hadoop Training field.