


By Ganapathi Devappa .
Initially the creation of digital data was limited due to the time it took to create the data and also limited number of people who were producing the digital data. But in the last few years, the time it took to create the data has reduced drastically. There are even instruments called sensors that can produce data even when not attended by a human being and that too at rates of many times per second. So the number of data creators has increased many folds. People are also producing digital data for more hours in a day, even when they are not in the office, commuting and on weekends. Such massive data needs efficient storage.
HDFS means Highly Distributed File System. HDFS is part of Apache Hadoop. HDFS provides the file system on which hadoop map reduce jobs can run.
Why HDFS?
One of the key advantages of using HDFS for storing your Big Data is economy. For example, if you have say 50TB of data to store, traditional SAN and network based storage will probably cost you about $40,000 per TB. So it will cost you roughly $2M for 50TB of data. With HDFS which uses commodity hardware in JBOD(Just a bunch of disks without RAID or NFS mounting) disk configuration with default replication of 3 will probably cost you about $150,000 ( for a 15 node cluster). This is less than one tenth the cost! This is one of the main reasons that many large organizations are adopting Hadoop HDFS for storage.
Other advantages of HDFS are:
- auto distribution of data,
- makes tape backups redundant
- auto redundancy
- built in fault tolerant architecture .
HDFS Design Principles
The key design principles of HDFS are:
- Hardware failures are common so system has to be highly fault tolerant
- Designed for large files – Terabytes and Petabytes
- Simple coherency model: Create once and read multiple times
- Streaming data access
- Moving computation is cheaper than moving data
- Portability across heterogeneous hardware and software platforms
Storage
HDFS system consists of a cluster of machines called nodes. In HDFS, each file is divided into blocks and stored. Each block is replicated 3 times by default. A large block size is chosen so that large file reads can be faster with streaming I/O. Default block size is 64MB but frequently block size of 128MB is chosen. Replicas of the same block are stored on the different machines of the cluster so that even if a machine fails the block data can be read from other machines. With 3 replicas per block, even if 2 machines fail, the data can be recovered.
HDFS is rack aware – If you specify the racks for a node, then block replica placement takes care of rack topology. First replica of a block is randomly placed on a node. Second replica is placed on a rack that is different from the first rack. Third replica is place on a different node on the same rack as the second replica.
Usage
HDFS provides java class interfaces so that you can programmatically access the file system including create, write and read the files. As it is a write once read many times file system, you can write only at the end of a file and cannot update contents of the file already written.
HDFS is used internally by many of the Apache Hadoop tools like Map/Reduce, Pig, Hive etc. When you are using these products, you don’t have to deal with HDFS files separately unless you have to manipulate the input and output for these programs.
HDFS also provides command line interfaces so that you can access it like the Unix or Linux file system. To copy a file from your directory to HDFS, use the following command:
HDFS dfs –put myfile myhdfsfile
To check the contents of your user directory in HDFS, you can use the following command:
HDFS dfs –ls
Check with your administrator to make sure your user id is properly set up for HDFS so that the above commands work. If they give any errors, it is not the command’s fault but your administrator has not set up the system properly.
To retrieve the data from HDFS, use the below command:
HDFS dfs –cat myhdfsfile
Above command will show the data of the file you have just put into HDFS. This works like the Unix cat command.
You can also use the web interface to navigate HDFS and look at the files and directories. I will come to that little later.
HDFS Daemons
HDFS file system is managed by three types of daemons (daemons are scheduled processes on Unix/Linux that run in the background like windows services or your mail server) as follows:
- Name node: This is the master node of HDFS. There is only one name node per name space. Name node maintains the metadata for the file system. It does operations like create, open, close and renaming of files. It monitors the health status of the file system and takes care that files are replicated properly.
- Data node: This is the slave node of HDFS. There can be any number of Data nodes, tens to hundreds to thousands depending on the data need. Data nodes hold the disks that store the actual data. The disks are not shared on the network and are tied to the Data node only. Data nodes regularly send a heart beat signal to Name node indicating that they are alive and can process data.
- Secondary Name node: This is a misnomer and secondary Name node is not actually the backup node for the Name node. It is a check point node that keeps the file system image on the disk updated from the edit log maintained by the Name node. I don’t normally recommend using a secondary name node as it is better (not easier though) to keep a stand by name node instead.
In addition, the client machines that run the HDFS programs can be different from the above machines. Client machines are not really part of HDFS but do the operations of connecting to Name node and Data nodes to create data in HDFS as well as retrieve data. They need to have the HDFS libraries to be able to communicate with HDFS.
Let me illustrate the HDFS file system with an example.
Let us take a 300MB file being put into HDFS with the following command:
hdfs dfs -put myfile myhdfsfile
If the default block size is 64MB, then file will be divided into 5 blocks, each block of size 64MB. The fifth block will contain less than 64MB of data. Let us assume a cluster of 5 nodes. Then these files will be stored as follows:
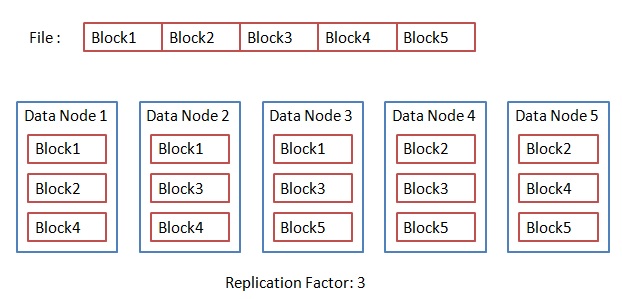
HDFS Operation
Now let us look at how these nodes work.
Name node is responsible for keeping the file system metadata up to date. The persistence of metadata is maintained through two files, fsimage and editlog. Fsimage has the view of file system metadata when the Name node started. Name node reads the fsimage into memory. Any changes to the file system (creation of file, update of file, deletion of file etc) are updated in memory and written to the edit log file. The fsimage file is not update. If the Name node fails, the in-memory copy of fsimage is lost but the file system state is recovered by reading the fsimage file from the disk and applying changes from editlog file. The process of updating the fsimage file with the changes from editlog, so that fsimage reflects the current file system state is called check pointing (from the database terminology).
This check pointing occurs only once when the Name node starts.
Name node does not keep the information about where the blocks are stored on the disk. This information called block table is kept in memory only. This table is updated as each Data node connects to Name node through a heartbeat signal. A heartbeat signal is sent by each Data node to the Name node regularly. When the Data node first starts up, it sends the block table information about the blocks stored on that Data node to the Name node. Thereafter, it sends this information about every hour.
Name node tracks the Data nodes through the heartbeat signals. If the Name node does not get heartbeat signal from a Data node for specific period, it marks the Data node as dead and after some time, it marks the blocks stored on that Data node as under replicated. Name node eventually orchestrates the replication of the under-replicated blocks through the Data nodes. Name node never reads any block of data either while creating the file or while replicating the blocks.
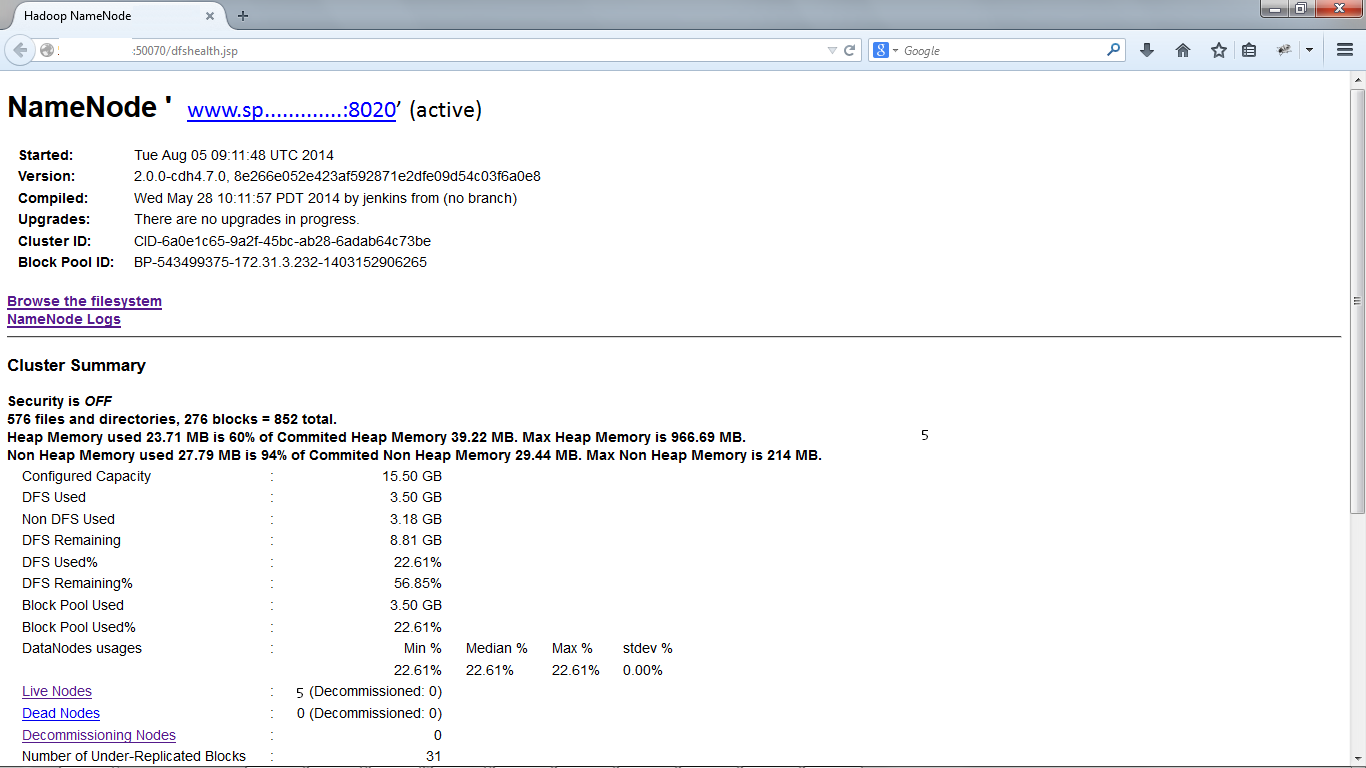
File system health can be checked by the automatic web interface provided by HDFS. The default port is 50070. For example if the HDFS name node is running on urlHDFS, the web interface can be accessed through http://urlHDFS:50070
Here is a screenshot of HDFS cluster (IP address has been deleted):
How do all of these fit together? Let us take some use cases and explain.
Writing a file to HDFS
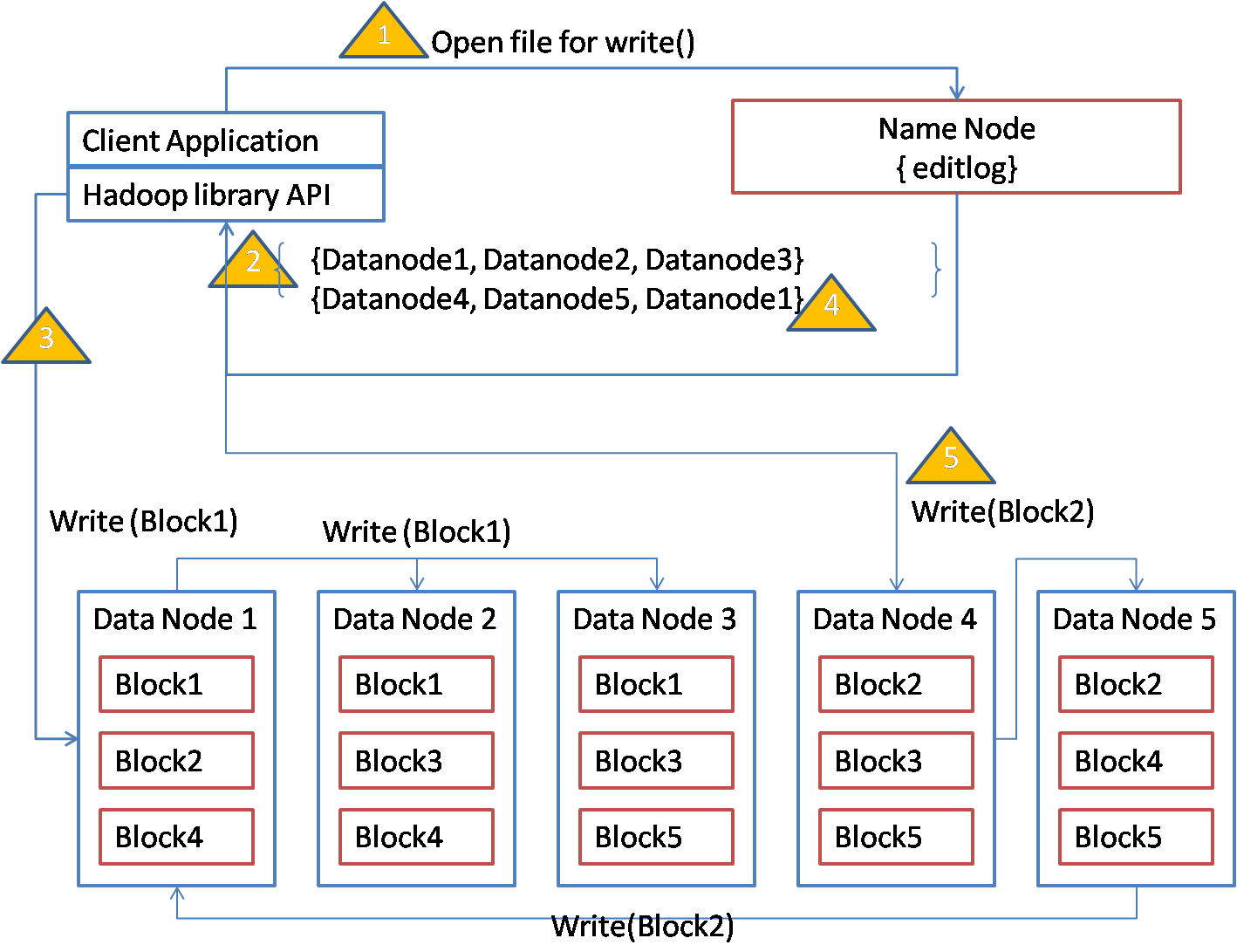
- Client program connects with HDFS Name node to open a file for write.
- If client permissions are ok, name node creates the file if it doesn’t already exist and returns the set of data nodes to which the first block can be written. Name node creates an entry in the disk image for the file and also makes an entry on the edit log on disk.
- Client sends the first block to the first data node in the list. The data node writes the block on its disk and sends the data to the next node in the list for write. That node sends the data to next node in the list till the data is passed to all the nodes in the list.
- Upon receiving acknowledgement from the data nodes, client program gets the set of data nodes for the next block from the name node.
- Client then sends the next block of data to the first data node in the list as before and data gets written to all the data nodes in the list.
- When all the data is written, client closes the file.
In the entire process, name node never gets the data from the file. Also as long as minimum number of replicas is written for a block, the block write is considered as success and file write succeeds. If some blocks are not fully replicated, name node will periodically try to replicate the blocks by instructing the data nodes that have the replica to write to other data nodes.
Reading a file from HDFS

- Client program connects with HDFS Name node with the file path
- Name node checks the file permissions from the in-memory file system image and if satisfied, sends the list of blocks to the client. As each block is stored on multiple Data nodes, the list is sorted by the Data node nearest to the client first.
- Client connects to the first Data node in the list and reads the block by streaming. Similarly it reads the next block till all the blocks are read. If the read from any data node fails, it tries the next data node in the list.
- When all the blocks are read, file can be closed by the client.
This is illustrated in the diagram below. Note that name node never gets any block of data.
Handling Failures
Disk Failure
When a disk attached to a data node fails, the data node detects the disk failure and sends an update block report, excluding the blocks on the failed disk to the name node. The name node marks these blocks as under replicated and eventually gets new replicas created for them. The new replicas may be created on a different disk on the same data node or on a different data node.
Data node failure
Data node indicates that it is alive through the periodic heartbeat signals to the name node. When the data node doesnot receive the heartbeat signal for a period of time, it marks the data node as dead. After some more period of time, name node marks the replication count of the blocks on that data node and manages to get new replicas created for the those blocks.
If the data node is fixed it can rejoin the name node by sending heart beat signal and block report. Then the replication count for those blocks will be increased and remain high till the name node reduces the number of replicas as space is needed.
Name node failure
Name nodes are a single point of failure in HDFS. If a namenode fails, then no data can be retrieved as meta data is not available. If you restart the name node, then it can recover from failure by reading the fsimage file and applying the changes from editlog file. If these files get damaged, then you cannot recover the system. If you have a secondary name node, then you can start a name node on the secondary name node by using the fsimage file check pointed by the secondary name node. You can also set up high availability for name node by setting up a stand by name node instead of a secondary name node.
I hope this has given you a good understanding of HDFS.
My blogs are normally short but here I have spent more time as HDFS has lot of things to offer and it is good to understand it well. I hope this encourages you to use HDFS in your organization for your Big Data needs. There are many more topics on HDFS like High Availability and security. I will cover these in a later blog.

Ganapathi is an expert in data and databases. He has been managing database projects for many years and now is consulting clients on Big Data implementations. He is a Cloudera certified Hadoop administrator and also a Sybase certified database administrator. He has worked with clients in US, UK, Australia, Japan and India on many large projects. He has helped in implementing large database projects in Sybase, Oracle, Informix, DB2, MySQL and recently SAPHANA. He has been using big data technologies like Apache Hadoop and SAP HANA and has been providing strategies for dealing with large databases and performance issues. He is based out of Bangalore, India. He can be reached at ganapathid@spideropsnet.com.
thanks for sharing nice information…
Great Blog | I appreciate your work on Hadoop.