

By Ganapathi Devappa,
Introduction to MapReduce
With HDFS, we are able to distribute the data so that data is stored on hundreds of nodes instead of a single large machine. How do we distribute our processes as well so that we can process the large file that now sits on these clusters of machines? Grid computing has been used for processing on multiple clusters of machines but has been very complicated to configure and setup. Parallel processing has also been around for long time but very difficult for programmers to understand and implement. Apache Hadoop MapReduce has been specifically created for this purpose.
Mapreduce provides the framework for highly parallel processing of data across clusters of commodity hardware. It removes the complicated programming part from the programmers and moves into the framework. Programmers can write simple programs to make use of the parallel processing.
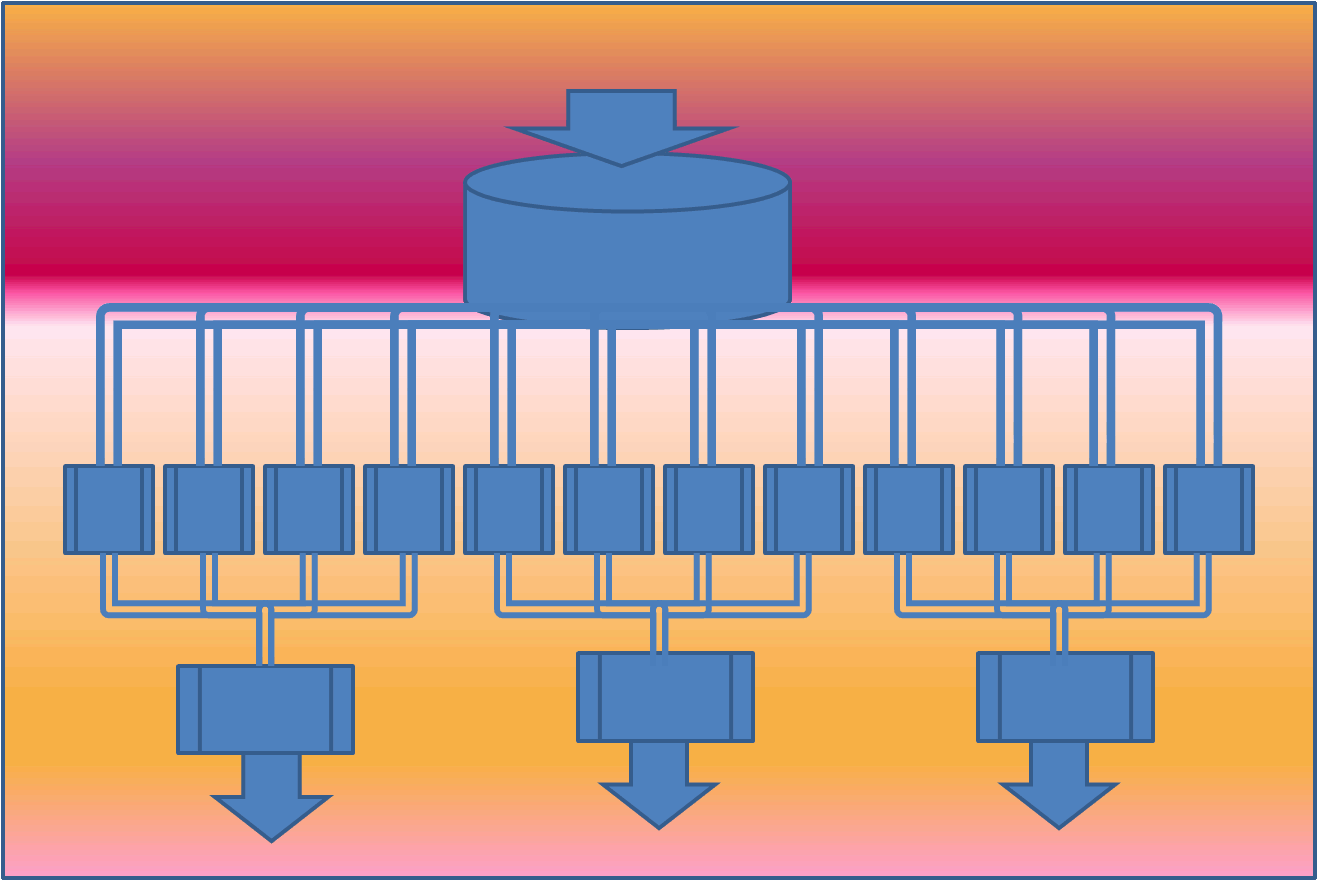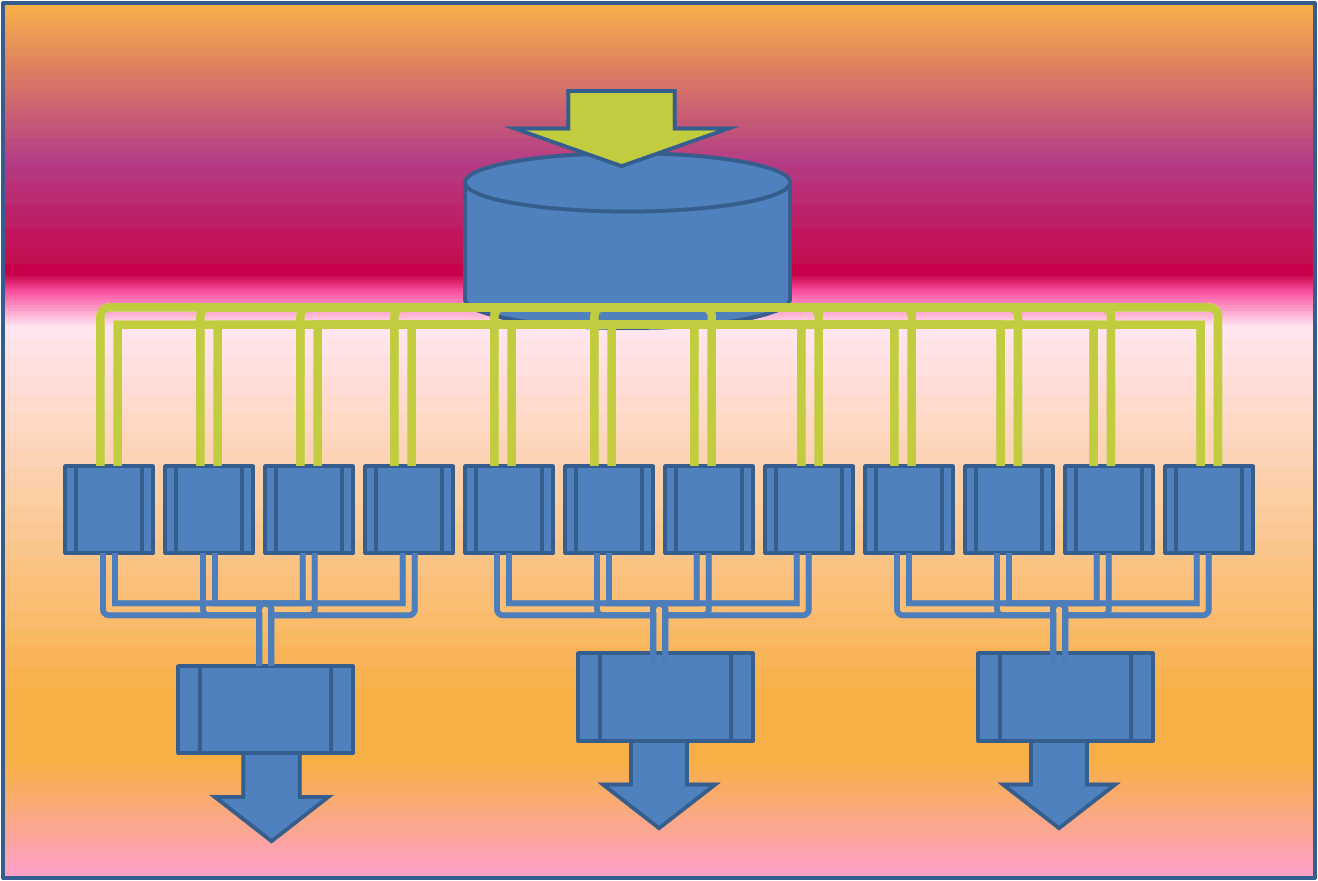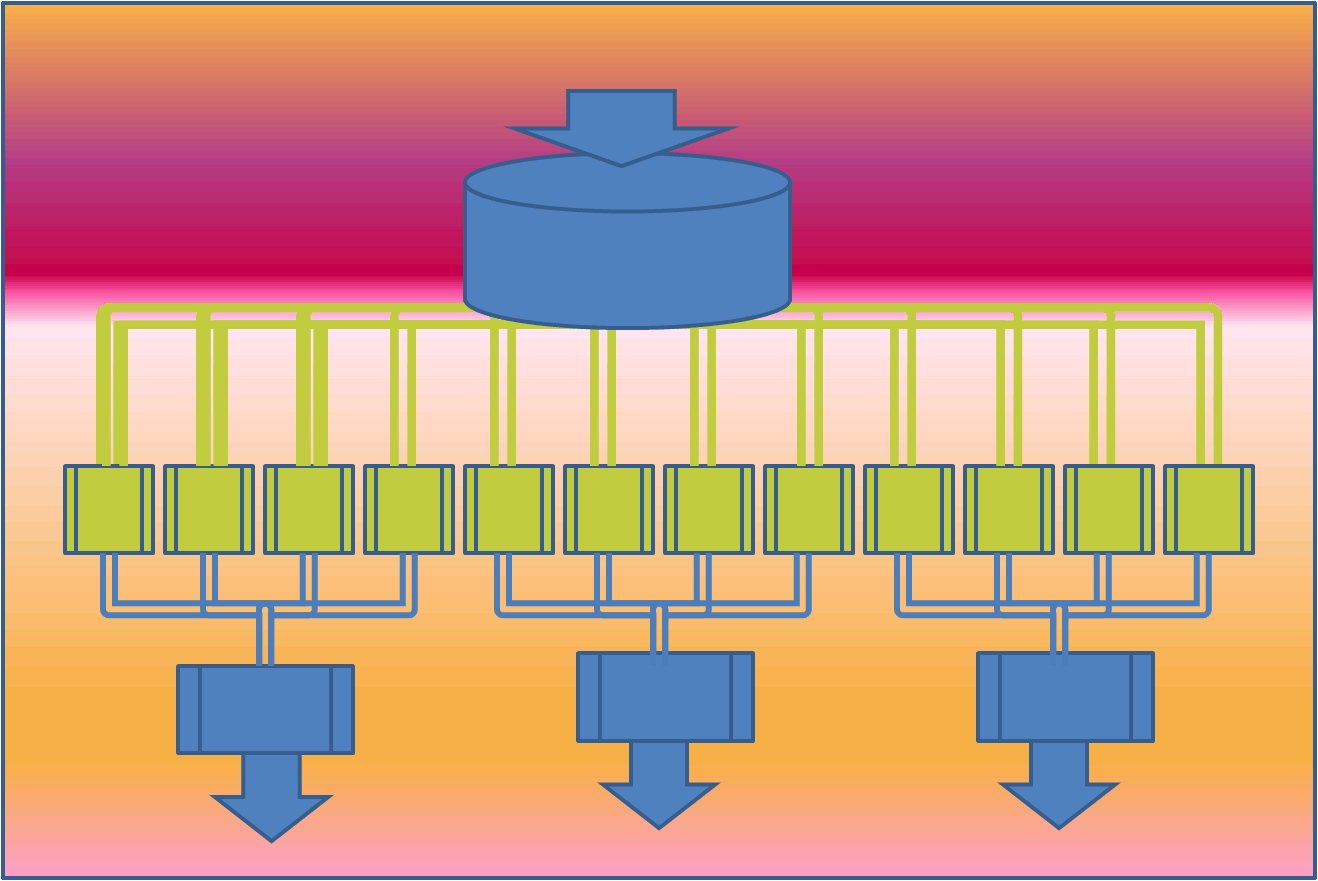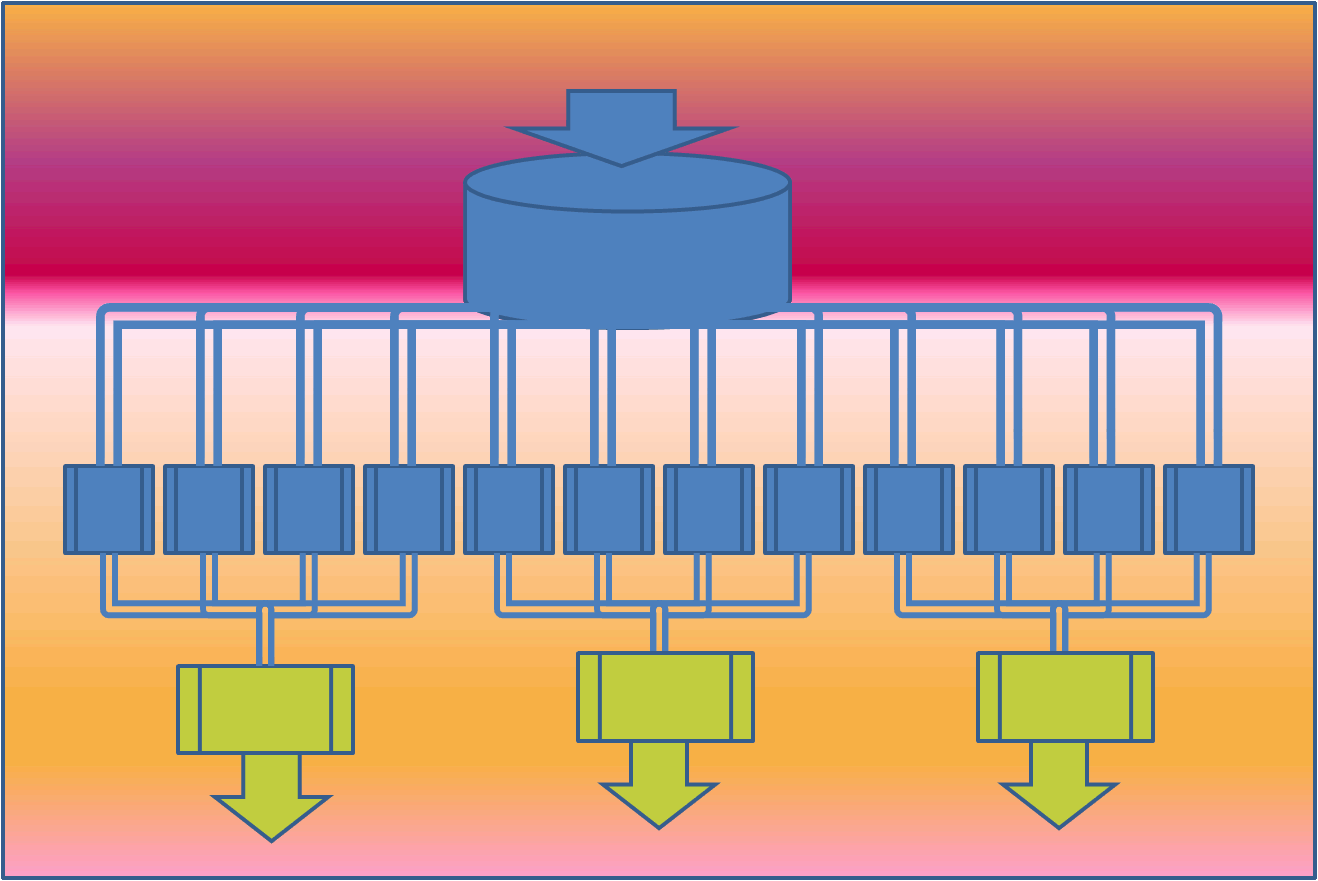
The framework splits the data into smaller chunks that are processed in parallel on cluster of machines by programs called mappers. The output from the mappers is then consolidated by reducers into desired result. The share nothing architecture of mappers and reducers make them highly parallel. This is illustrated in the following figure:
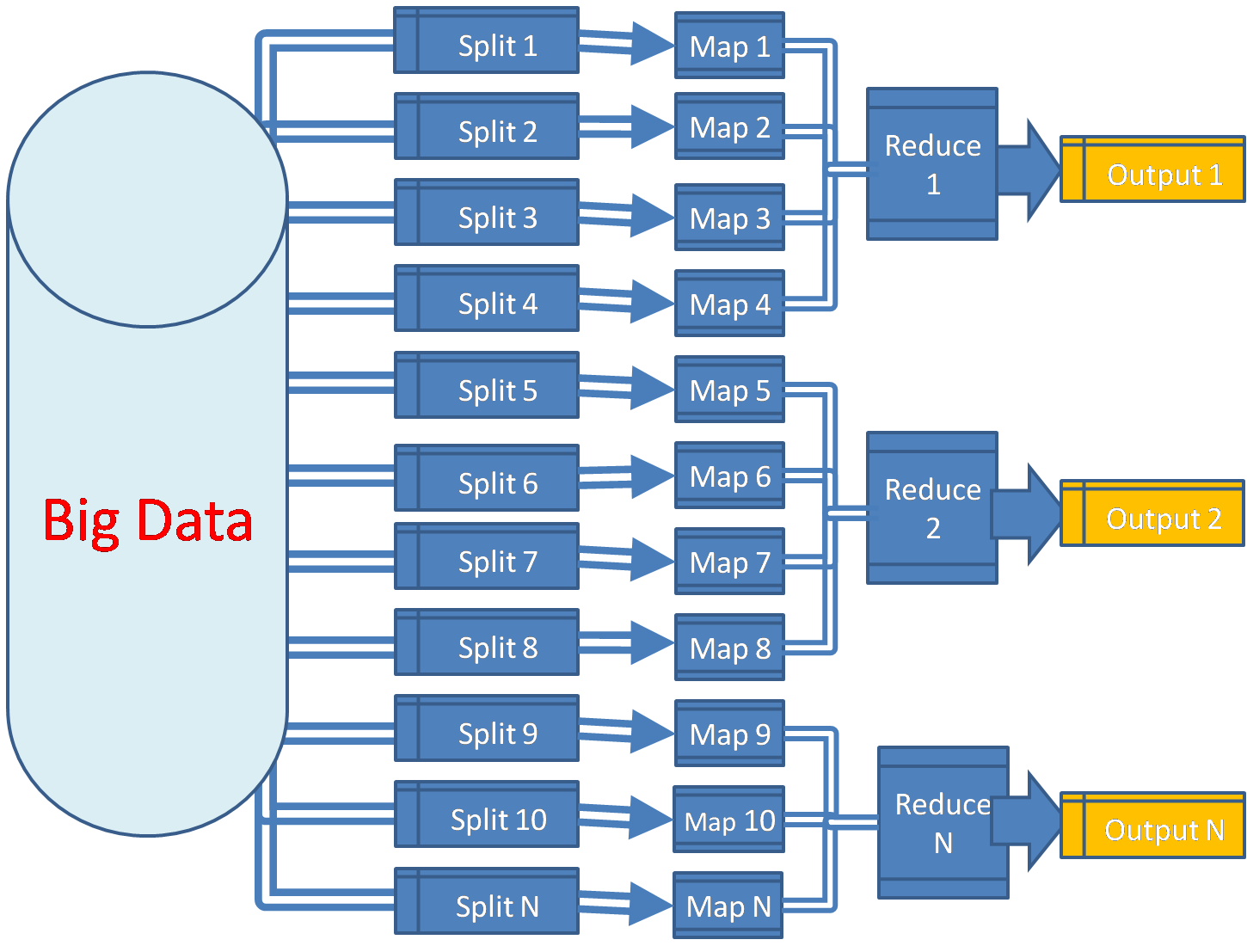
The mappers above work independently of each other and hence can be scheduled on any processor.
-
MapReduce Principles
– Simplicity of development
Developers don’t have to worry about the plumbing for their jobs. No threads or inter process communications or semaphores to program. Just write programs that process part of your input files and produce the output. This shields the developer from all the nitty gritties of parallel programming.
– Scale
The mappers and reducers share nothing. That means each mapper is independent of what other mapper does and each reducer is independent of other reducers. So the mappers and reducers can be massively parallel. So if you have 10 nodes and each is capable of running 10 mappers, then you can split a job into 100 tasks that can run in parallel. If you have 128MB block size, then you can easily run a job that takes 128MB * 100 ie 12.8GB of input file. If your file can be processed at 100MB/second, then 128MB block can be processed in less than 2 seconds. So the map reduce job may take 2 seconds to process the 12.8GB file where as a serial job would have taken 128 seconds or more.
– Automatic distribution of work
With map reduce paradigm, the mappers process one record at a time, so the framework can divide a file into any number of pieces at the record boundaries to execute as parallel tasks. The framework automatically divides the input file into chunks of records for processing by mappers.
– Fault tolerance
The map reduce system is built for failure. The machines can be commodity class machines meaning failures can happen any time. So the system is built robust so that the users don’t have to take any action and the system automatically handles the failures. For example if a machine running a mapper fails, that mapper is automatically scheduled on another machine.
– Commodity hardware
Economy is very important for map reduce. The machine is not expected to be high class but performance is achieved through parallel processing and data locality.
– Data locality
It is faster to bring processing to data than data to processing. Getting data from a local disk to memory is much faster than getting data over the network. Map Reduce framework tries to reduce transfer of data over the network by running the tasks on the machine where the data exists.
So by scheduling tasks to handle a block of data on the machine where the data is present, the overall processing time is drastically reduced.
Mapreduce and HDFS
Data locality mentioned above is achieved by mapreduce by working closely with HDFS. When you specify the file system as HDFS for mapreduce (through a configuration option), mapreduce automatically schedules the mappers on the same node as where the block of data exists. Mapreduce can get the blocks from HDFS and process them. The final output from Mapreduce also can be stored in HDFS file system. However, the intermediate files between mappers and reducers are not stored in HDFS and are stored on the local file system of the mappers.
Stages of MapReduce
1. Client job submission
Map reduce framework provides the apis for client job submission. Jobs can be submitted from command line as well using the Hadoop libraries. A streaming facility is also provided so that you can use python/shell scripts as map reduce jobs
2. Map task execution
Each job is divided into multiple map tasks. Number of map tasks is decided by the input splits. The input file is divided into splits that are distributed to the map tasks. By default, the HDFS block size is chosen as the split size and one map task is initiated for each HDFS block of input. Data locality is achieved by running the map task on the same machine as the HDFS block.
Map tasks do not share anything between them and are run in parallel. Multiple map tasks may run on the same machine in parallel if the machine has more than one map slot available and also has multiple blocks of the input file.
3. Shuffle and sort
Output of map tasks are shuffled and sorted before presenting to reducers. The map reduce framework takes care of the shuffle/sort. The framework guarantees that the keys are ordered and all the values for a particular key are presented to the same reducer.
4. Reduce task execution
Reduce tasks take the shuffled output and provide the results by aggregating data from all the mappers. As many output files are produced as the number of reducers. Reducers also do not share anything with other reducers and hence can run in parallel.
MapReduce daemons
Mapreduce system is managed by two types of daemons (daemons are scheduled processes on Unix/Linux that run in the background like windows services or your mail server) as follows:
1. Job tracker
There is a single job tracker that runs on the master node. It is the driver for the mapreduce jobs. Its functions are:
– Accepts jobs from client and divides into tasks
– Schedules tasks on worker nodes called task trackers
– Keeps heartbeat info from task trackers on worker nodes
– Reschedules the task on alternate worker if a worker fails
2. Task tracker
Task tracker runs on each worker node and there are as many task trackers as the worker nodes. If HDFS is also used, then data nodes of HDFS also become worker nodes for task tracker. The functions of a task tracker are:
– Takes assignments from job tracker
– Executes the tasks locally
– Each worker node has specific number of mapper and reducer tasks it can take at one time
– The tasks assigned are run in parallel
– Normally they can take more map jobs than reduce tasks
– Task tracker does a task attempt before executing task
– Task tracker may do multiple attempts before declaring a task as failed
– Task tracker maintains a connection with the task attempt called umbilical protocol
– Task tracker sends a regular heartbeat signal to job tracker indicating its status including available map and reduce tasks
– Task tracker runs each task attempt in a separate JVM. So even if the task has bad code due to which it fails, it will not cause task tracker to abort.
Handling Failures
-
Child task failures
A child task can exit with an error status or may abort with an exception. Task tracker detects the status and reports failure to job tracker. Task tracker also expects the child task to regularly update some metrics. If the child task goes into an infinite loop and does not update the status or metrics, then also task tracker will detect the task as failed and kill the task.
Once the job tracker receives the status that the task has failed, it will reschedule the task on a different worker node. If the task fails 4 times (this is configurable), then the whole job is marked as failed. If many tasks fail on the same worker node, then the node may be back listed for 24 hours. New tasks will not be scheduled on back listed nodes.
-
Task tracker/worker node failures
If the job tracker does not get heartbeats from a worker node for a considerable period of time, then the worker node is marked as dead. Any tasks that were scheduled on that node are rescheduled on other worker nodes. Client application will not see the failure but may see slow down as tasks are rescheduled.
-
Job tracker failures
If the job tracker itself fails, then no jobs can run and all the jobs that are running need to be rerun after restarting the job tracker. Job tracker is a single point of failure. So the job tracker is normally run on master nodes that have better hardware configuration than worker nodes.
-
HDFS failures
If a datanode fails, the tasks that are running on that machine will be retried on other nodes. If the namenode itself fails, then no new jobs can be started and the running jobs will fail as they cannot write the output to HDFS.
Mapreduce web monitor
Like HDFS, Map/Reduce also provides a web interface for monitoring. It can be accessed at port 50030 of job tracker node. You can see the running as well as completed/failed jobs and drill down to each task level.
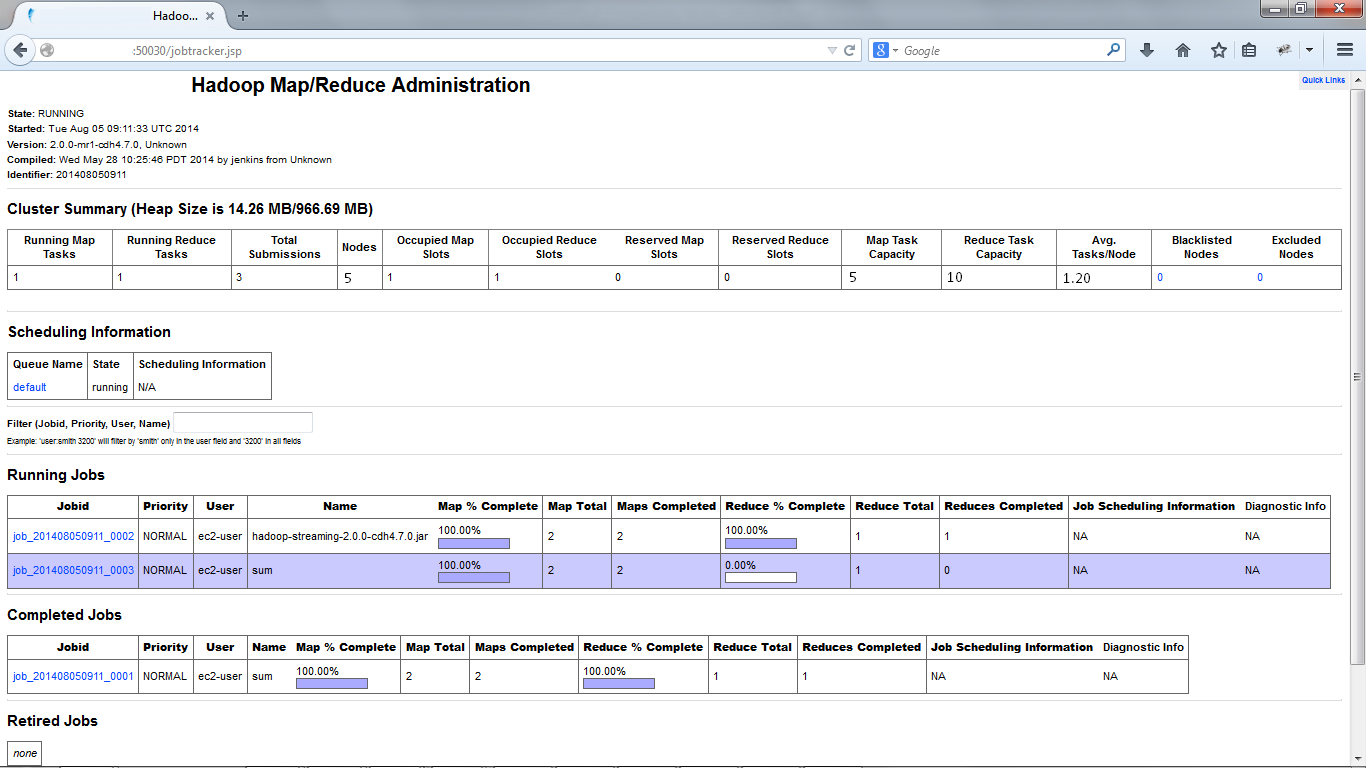
The ip addresses in the above page are blanked out.
You can also configure to use tools like Ganglia to monitor the processes and cpu usage on running tasks. The framework allows the monitoring information to be consolidated and shown at the job tracker level.
Illustration
Let us take the example where the file had 300MB of data. Let this file be from the health care data where temperature of patients from last ten years is recorded and we need to find the mean and the standard deviation from the mean. The cluster is configured with the following parameters:
No.of datanodes : 5
No.of task tracker nodes: 5
No.of tasks on task tracker: 1 mapper and 1 reducer
Storing in HDFS:
You can store this 300 MB of data in HDFS (say comma separated lines). HDFS divides this into blocks of 64MB size by default and will give 5 blocks. With a replication factor of 3, this will become 15 blocks that will be stored on different machines of the cluster.
MapReduce processing:
Mapper: Mapper is programmed independent of the file size. It reads each record (a line in the file) and outputs the number of values, sum of values and sum of squares of values . This is stored as a temporary file by mapper and will not be stored on HDFS.
Input split 1 -> mapper 1 -> temp file 1(1500, 41456,1160335 )
Input split 2 -> mapper 2 -> temp file 2 (1500,42342,1207328)
Input split 3 -> mapper 3 -> temp file 3 (1500,43746,1291264)
Input split 4 -> mapper 4 -> temp file 4 (1500,42434,1213219)
Input split 5 -> mapper 5 -> temp file 5 (1032,30342, 900065)
[ last split has less number of records at is only 44 MB ]
The shuffle/sort stage combines all the above file contents into a single file as follows:
Input: temp file 1, temp file 2, temp file 3, temp file 4, temp file 5
Out put: temp file
Reducer: Only one reducer is required. Reducer gets the one file from shuffle/sort and produces the mean as well as the standard deviation based on the data above.
Temp file -> reducer 1-> output file (7032, 28.49, 3.03)
Reducer can be scheduled to run on any of the 5 nodes and the shuffle/sort will create the temp file on the machine where the reducer is scheduled to run.
As illustrated above, programmer had to consider only how to calculate the mean and standard deviation from intermediate results (in this case from sums and sum of squares from each file) and didn’t have to worry about how he is going to handle parallel processing. All this complexity has been taken away by the framework.
YARN
Apache has come up with a newer framework for mapreduce called YARN (acronym for yet another resource negotiator). This was done as original mapreduce could not handle very large size clusters appropriately. I will discuss about YARN in a subsequent blog.
Conclusion
Apache Hadoop is a very powerful framework that can handle hundreds of cluster nodes in parallel in an efficient fault-tolerant way. HDFS provides a framework to distribute the data. Mapreduce discussed in this article provides the framework to run a job as hundreds or thousands of parallel tasks and removes the complexity involved in parallel processing from the programmer. These powerful frameworks can be utilized to tackle the most complex problems created by Big Data.
About the Author

Ganapathi is an expert in data and databases. He has been managing database projects for many years and now is consulting clients on Big Data implementations. He is a Cloudera certified Hadoop administrator and also a Sybase certified database administrator. He has worked with clients in US, UK, Australia, Japan and India on many large projects. He has helped in implementing large database projects in Sybase, Oracle, Informix, DB2, MySQL and recently SAPHANA. He has been using big data technologies like Apache Hadoop and SAP HANA and has been providing strategies for dealing with large databases and performance issues. He is based out of Bangalore, India. He can be reached at ganapathid@spideropsnet.com.
Nice blog| I have gained good knowledge about Hadoop.